Snowflake - Apple Of MDS - Part 2
Summary
- SNOW's lead on the computer engine side is still there, but not guaranteed as others are catching up fairly quickly.
- SNOW's proprietary storage format plus native support for Iceberg is a strong strategy against Databricks and many other players.
- SNOW's moat and business model hinges on further use of structured data (CDW), expansion into data science, and its moat deepening by scale and vertical expansions.

reklamlar/iStock via Getty Images
Overall, we believe SNOW is strongly positioned, both at the architectural/technological level and the strategic level, for both compute, storage, and beyond. At the same time, we see SNOW's edge is diminishing quickly as tons of competitors catch up on the technical fronts, big corporations pour resources into this field, and startups take money from VCs who want to repeat SNOW and SHV's success.
Investors need to be aware that although OLAP (Online Analytics Processing database) and CDW are hard to build, they are not impossible to build. And there are 10+ more teams/companies that can build the architecture/product akin to SNOW. The motivation for new entrants couldn't be stronger as SNOW is now targeting $10bn+ in revenue with 80%+ gross margin.
For the compute aspect, we are going to assess whether Databricks' Photon claim holds true, and whether SNOW has the competitive edge to fend off Starburst, Ahana, Dremio, Firebolt, Redshift, and others.
For the storage aspect, we are going to assess the potential of Iceberg, Delta Lake, Hudi, evaluate SNOW's proprietary format, and understand SNOW's long-term strategy with regards to storage.
We will then cover Frank Slootman's vision and SNOW's expansion strategy, and consider the factors at play that will determine whether or not SNOW will secure its moat.
Compute
SNOW still very competitive on the core compute performance front, especially for the CDW workload. In cases such as data mesh, data science, real-time, and fine-tuned accelerated compute, SNOW is trailing behind but it won't kill the core business. We believe it will become harder for SNOW to justify the premium for compute as its gross margin is reaching 80%, which means users are paying 5x the raw compute cost to SNOW. Going forward, it will be easier for competitors to catch up and price the product more aggressively.
On the other hand, SNOW has a large degree of competitive protection as there are no secret tricks to achieve a 10x performance gain that would to disrupt SNOW - at least not until the next wave of architectural change kicks in. The separation of compute and storage, that utilises
- elastic compute,
- cheap object storage,
- high-speed networking of hyperscalers',
- columnar storage,
- vectorised and SIMD-based compute,
- and various other optimisation techniques to speed up the compute engine,
are basically the common standard for the latest generation of players. Managed as-a-service offerings, making everything easy to use with consumption-based pricing, is also a predominant trend in regards to the business model. All of these standards and trends mean that vendors will become more similar to each other over time. Hence, we don't believe SNOW needs to worry that much about the next-gen architecture that will emerge, but more about deepening the moat via fine graining the use cases and by developing advanced features above the CDW, which we will cover later.
Databricks Photon
The most notable recent buzz was sparked by Databricks with its newly released Photon engine that specifically targets warehouse workloads. In their Nov 2021 blog post, Databricks claimed that its Databricks SQL-based Photon engine is 2.7x faster and 12x cheaper than SNOW's.
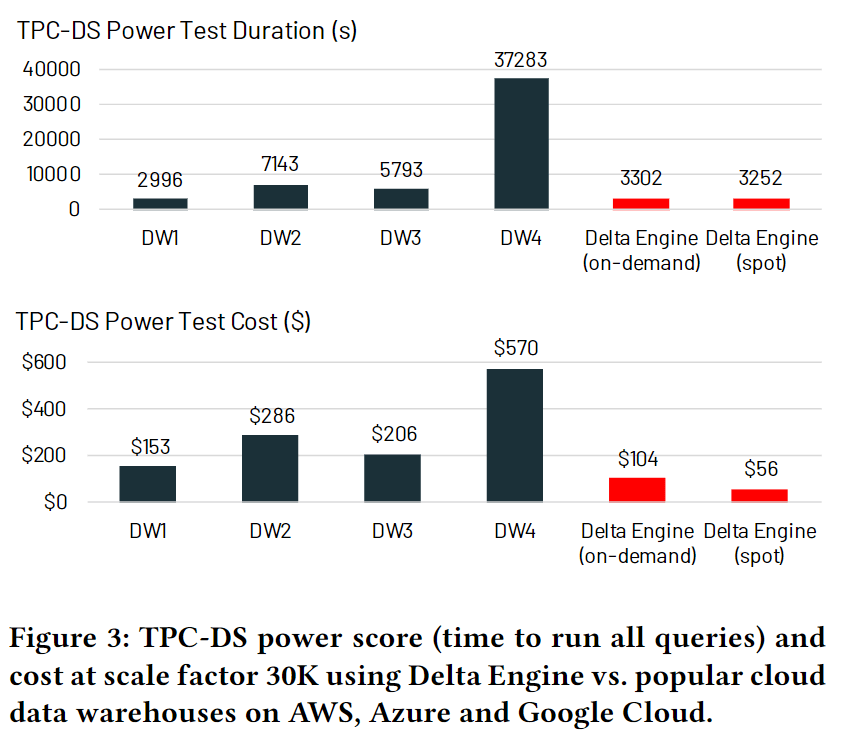
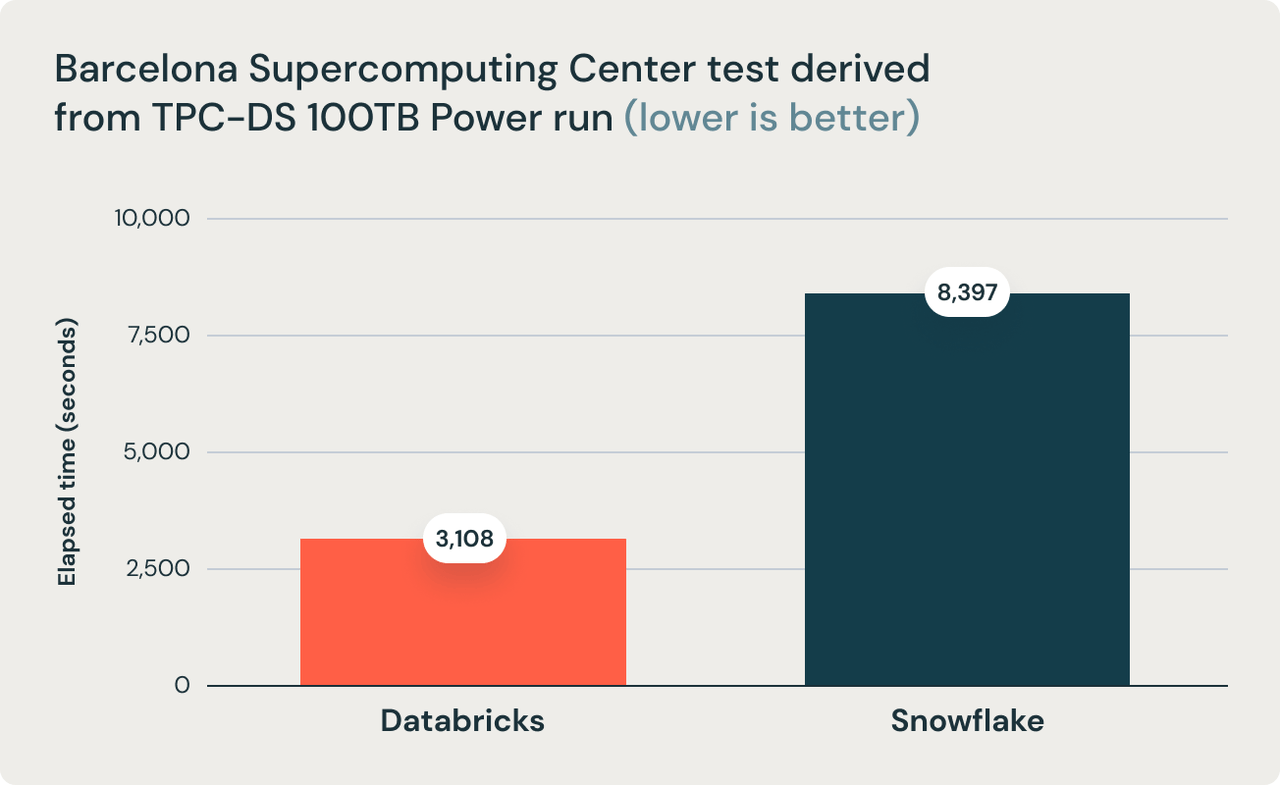
Databricks Sets Official Data Warehousing Performance Record
To start with, we believe Databricks is indeed the biggest threat to SNOW right now, and public investors don't cover it well enough. From the beginning, practitioners have widely suspected that Databricks is going to enter the SQL and warehouse world because, although Apache Spark was created as a big data compute framework, most of its end-use cases are tied to BI (Business Intenlligence), which is the same as CDW.
Furthermore, despite Spark being designed for sophisticated data scientists and engineers who can write codes in Scala, Java or Python, the most popular language and module on Spark is actually SQL. SQL is the de facto language used by CDWs because non-coders like business analysts and executives can get onboarded with SQL and gain value from it very quickly. This post published in 2015 detailed it very well.
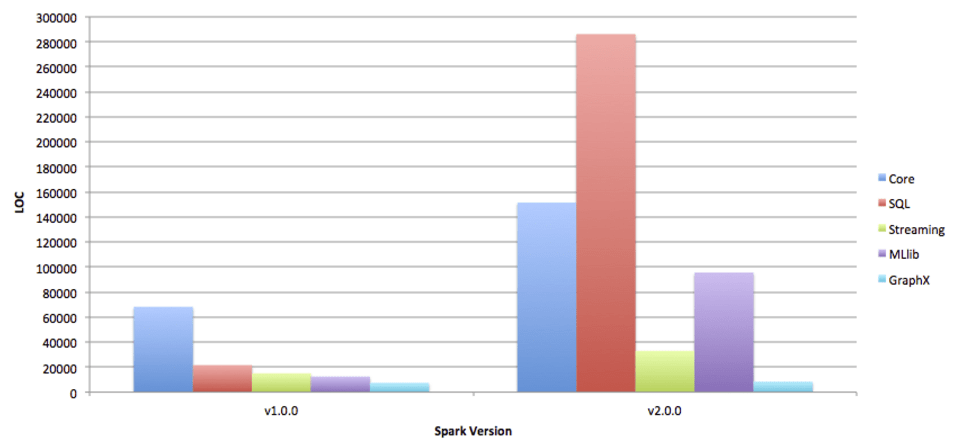
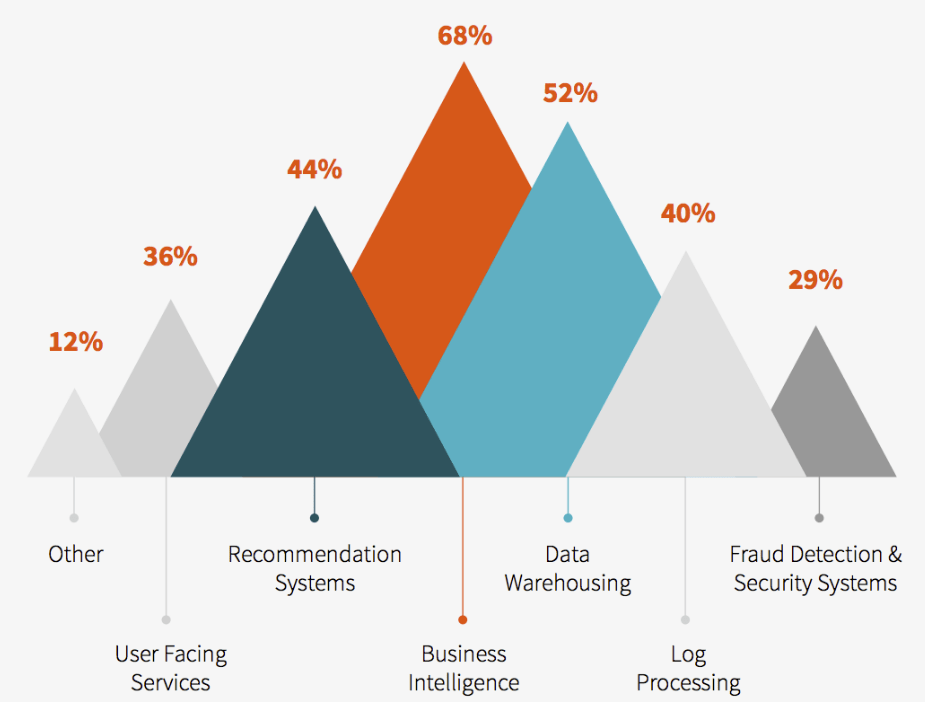

As a result, although Databricks and Apache Spark led the rise of the data lake and created the second generation of the big data industry, to expand the market they must go into the data warehouse space, both on the compute and storage sides. Or a more cynical take is that the concept of unstructured data, data lake, and data science are fancy terms to describe data that is yet to find value. The majority of valuable data is in the form of structured data within DW instead of DL. Furthermore, as we enter the age of data apps and RETL (Reverse Extract, Transform, Load) - the second order, higher level use of data & OLAP - the value of DW and its importance will only grow stronger.
Apache Spark was designed to be a compute engine that could be multi-purposed when various modules are used. It was originally designed to support the Hadoop File System (HDFS) for the on-prem world. Hence, the file system wasn't optimised for structured data but rather more general purpose files.
This is why Databricks has spent more energy in recent years building Delta Lake and Photon - the DW storage system that lives in tandem with the previous DL, and the DW SQL compute engine that lives in tandem with previous Spark modules.
Databricks has been more pressurised than SNOW because it has had to establish a strong footing into DW otherwise it will lose the most valuable and growthy part of OLAP. The team was super adaptive from the start. The initial Spark GTM wasn't successful as it was created as an academic project, resulting in a less refined package, as researchers need to test and configure things quickly. Databricks then rebuilt the open-source Spark as Databricks Spark, which became the close-source version accessible only as-a-Service on the cloud. It turned out to be highly successful as most enterprises wanted an out-of-box and easy to use product, even though the assumed core users, such as data scientists and data engineers, ought to be more willing to deploy and optimise on their own.
Databricks realised it had to build a vastly more performant and efficient DW compute and storage engine in order to beat SNOW, which was already quickly penetrating the market and becoming the undisputed CDW leader. Therefore, it spent tons of time doing heavy engineering work to rewrite the Spark SQL in C++, using every optimisation technique possible, including SIMD and vectorisation.
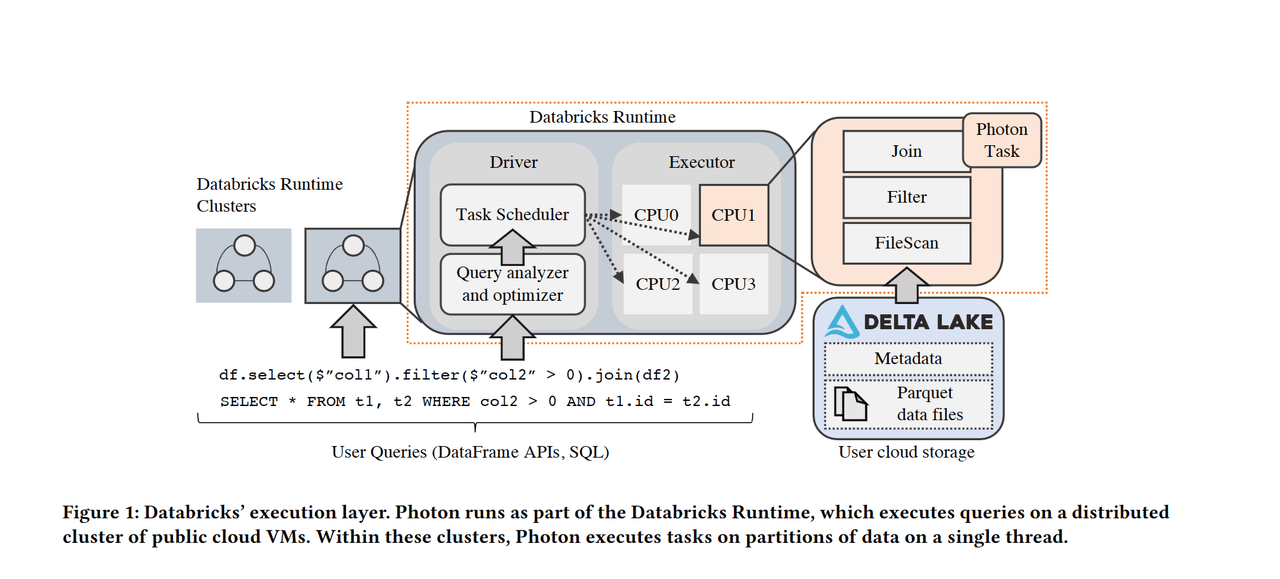
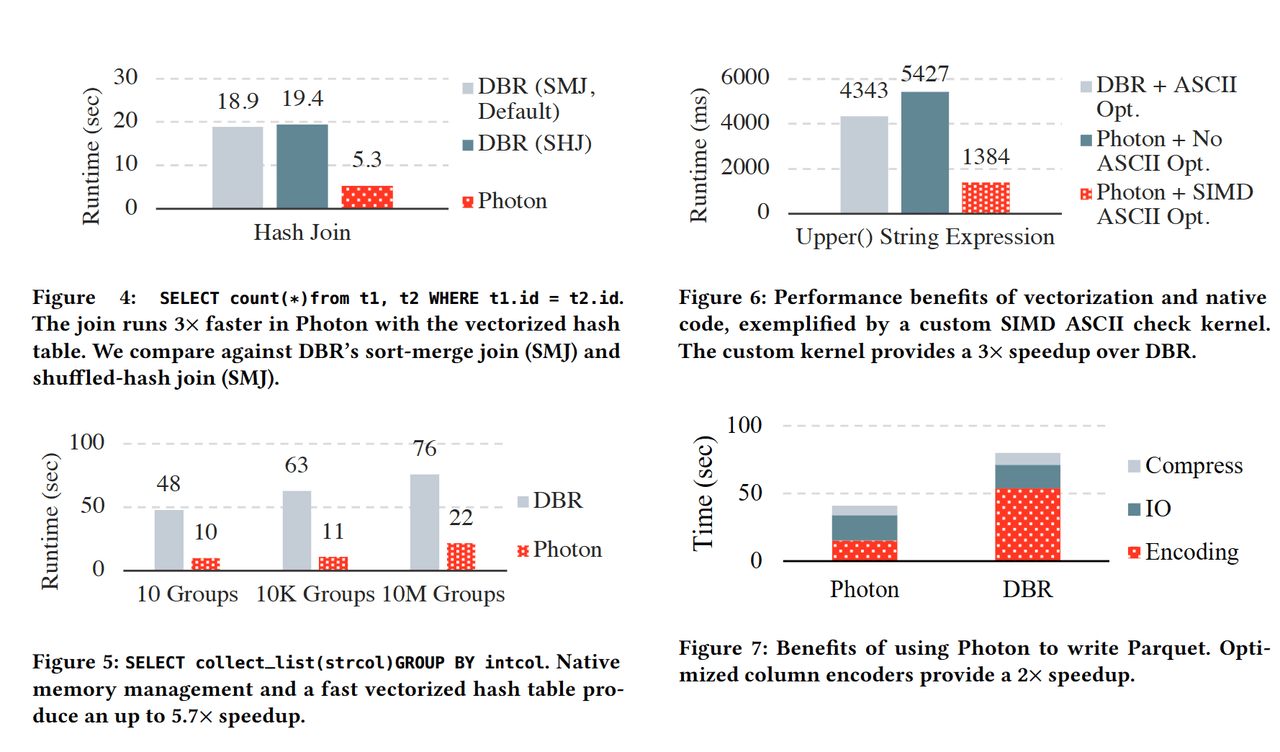
https://cs.stanford.edu/~matei/papers/2022/sigmod_photon.pdf
The end result is a 2x+ speed up vs. Spark SQL. This is to be expected as previously other developers outside of Spark contributor community have delved into ways to optimise it. Spark was written in Scala with JVM (Java Virtual Machine) involvement. As a result, you can't granularly control the memory, but the application is easy to code and develop. C++ allows developers to fine tune every piece of memory but it is way more time consuming and less agile to develop. Spark's execution also includes the translation between columnar and row, rendering a performance overhead. Previously Intel's OAP, and Alibaba's EMR have partially optimised Spark with their own distribution. Most notably, Alibaba's optimised Spark was the previous TPC-DS world record in 2020 before Databricks released its own native version Photon.
So, does Databricks' claim hold true? Our research suggests that it has a noticeable, but not a great lead, over SNOW in certain use cases. But overall, the claim that it is 3x-12x better than SNOW is a pure marketing game. SNOW is better at CDW workloads that are smaller and with data sharing involved. Databricks Photon is better at batch jobs as it still lives in Spark, which was originally designed for heavy batch workloads that run across multiple machines for days rather than in seconds.