

Themes: Modern Data Stack
This is a free post that has also been shared on Substack. It is a high-level overview of the Modern Data Stack. For more detailed insights please search for our reports related to Snowflake.
Summary
We discuss the journey toward the Modern Data Stack, what it consists of, key players to watch, and its emerging trends.
Snowflake's (SNOW's) Pros and Cons as the Modern Data Stack Evolves
Pros
- To increase the speed at which data turns into business insights, enterprises need more data to be structured, and structured data is Snowflake's core competence. Exploring raw, unstructured data is still valuable for data science use cases, but ultimately business decisions still need to be predicated on curated, structured data. Hence, OLAP workloads (i.e., queries against structured data in a data warehouse) will continue to hold the most value in the value chain. Therefore, as the lines blur between structured and unstructured, and between business intelligence and data science use cases, generally Snowflake should have the advantage over Databricks.
- Unlike Databricks, SNOW owns the storage layer, which is empowering it with many benefits, such as:
- optimizing the performance of OLAP workloads
- providing higher levels of security and governance
- facilitating a marketplace for data sharing
- enabling vertical-specific data clouds
- and developing an application building layer on top.
SNOW's competitors that only own the compute layer are limited in how they can optimize performance and expand their TAM.
- The promise of data applications, whereby applications are built atop data stores, should give SNOW the upper hand over Databricks. Applications of all types (consumer, B2B, enterprise AI) need to be built on curated data, which is SNOW's core competence.
- SNOW versus Databricks is a similar rivalry to Apple versus Google in the smartphone industry during the 2010s, as respectively, they are closed-source and open-source companies. During the 2010s, Apple delivered superior user experience by tightly integrating its software and hardware, and commanded a premium accordingly. Google played catch up by creating the open-source Android operating system to be used by smartphone makers, but because of the open nature, there was no standards for the app store nor the API service layer, resulting in poor user experience. In response, Google had to create more and more closed-source components to improve the quality, thus defeating the purpose of open-source. We are seeing Databricks do something similar to Google, which somewhat validates that SNOW's approach is likely the best approach for the Modern Data Stack.
Cons
- Contrary to the common investor perception, SNOW's most dangerous competition is from that of startups in the open source community, rather than Redshift and BigQuery. For instance, instead of using SNOW, an enterprise could use a combo of internal data engineering resources, an open-source storage layer, and an open-core vendor's compute layer, to construct something similar to SNOW. Done right, this would probably save costs (likely in the short-term but less likely over the long-term) but be unwieldy to manage. Therefore, it's possible we see a bifurcation whereby we see different players emerge dominant in the low-end and high-end of the market. We may see many large enterprises with sufficient internal resources or enterprises with a short-to-medium term focus on cutting costs, will choose the open-source/open-core alternative stack. And those enterprise customers in the higher end of the market will choose SNOW for its superior end-to-end user experience.
- SNOW's original competitive advantage of storage and compute separation has long evaporated as it is now the industry standard. This means SNOW needs to take on some risky ventures to expand its ecosystem and raise the entry barriers further.
- Compared to newer players, SNOW is weaker on the data source side of the Modern Data Stack, or MDS. As the demand for real-time data processing increases, as well as the demand for data mesh architectures that enable the querying of data at its source, SNOW could be at a disadvantage.
Brief History of the Journey to the Modern Data Stack
Since the dawn of the computer age, data storage has been in constant evolution. From the mainframe era's magnetic tape and disk storage to the 1970s' relational database (RDBMS) which catalyzed the IT boom, each advancement made database handling easier.
The advent of standards like SQL, the PC revolution, and the internet proliferation resulted in numerous applications and systems each requiring an RDBMS. This trend continued in the era of mobile, cloud, and SaaS, leading to data fragmentation and silos, creating obstacles for business analysis.
The inception of the first data warehouse (DW 1.0) provided a standardized data source, facilitating efficient analysis. This was later upgraded to cloud-based data warehouses (DW 2.0), such as AWS's Redshift, which eliminated the need for upfront server investment.
Snowflake launched DW 3.0, a groundbreaking approach that separated storage and compute, a method now industry standard. Concurrently, the emergence of Data Lakes (DL) met the need for storing diverse unstructured data, like social media content. AWS' S3 and other hyperscalers' object storage solutions became popular DLs.
However, DLs, while offering vast storage, lacked governance and weren't optimal for data querying and retrieval. They often devolved into data swamps due to poor quality data. Implementing structure and governance to enable SQL querying became necessary to tap DLs' potential.
We're currently seeing the convergence of DL and DW to facilitate DW-like analysis on DL data. For example, Databricks has evolved from big data and DL towards DW, introducing the term Data Lakehouse. Snowflake, likewise, expanded from CDW to DL, dubbing it Data Cloud.
New players are offering storage layers to transform raw DL data into useful datasets and adaptable compute layers for analyzing various data types. The collective aim is to help businesses efficiently analyze data, reduce costs, and accelerate data velocity for better business results.
What is the Modern Data Stack?
At the highest or most simplistic level, the MDS (Modern Data Stack) consists of data pipelines, centralized storage, and quick and flexible compute. The idea is to connect to and extract raw data from all types of sources (ERP, OLTP, CRM, web logs, IoT, etc.) and load (or transform and then load) the data into a centralized data store. Once the data is in a centralized data store, it serves analysts who need to query and analyze the data in order to generate business insights that lead to better business outcomes for their enterprise. The MDS also encompasses a number of emerging trends that aim to further curate data so that it is more time and cost-efficient to query and interact with.
What is driving demand for key players operating in the MDS?
The general investment thesis for any key player in the MDS is that it is very hard for enterprises to construct their MDS without third-party specialist support. Many times enterprises will begin building their MDS with in-house engineering resources to save costs, but the unexpected overheads and scarce talent required will usually lead to high TCO (Total Cost of Ownership) over time. Consequently, such enterprises will seek third-party vendor support to lower their TCO and speed up time to market. Some of the key challenges with constructing this MDS without support include:
- Building the data pipelines that connect sources of data to their intended destination, which is usually a centralized data store, but the pipeline most likely needs to also connect the source data to various intermediate points of data consumption (i.e., other applications that need input data) en route to the destination. This is extremely challenging to build in-house and even more challenging to maintain as data processing requirements inevitably change over time.
- Particularly for applications relying on real-time data, enterprises need to build distributed systems and data pipelines to ensure fault tolerance. Without fault tolerance, a real-time application wouldn’t be able to promptly recover from a disruption like a network outage. However, distributed systems are hard to build and maintain and requires ample engineering talent.
- Engineering the data pipelines with sufficient throughput to ensure a satisfactory freshness of data. This is especially important for those applications that require real-time, or near real-time, input data, or for those analysts who need fresh data to generate timely insights for the business. Again, this is extremely challenging because it necessitates highly distributed systems to process sufficient throughput.
- Oftentimes a data pipeline may need to transform the data as it moves from one point to another. For instance, source data from a legacy application may need to be transformed in order to be used by another application. Or the data may need to be filtered and joined with other data before loading into a centralized data warehouse ready for analysts to query. Doing this in-house with limited data engineering resources is fraught with risk, ranging from problems with data lineage (root cause analysis, upstream/downstream cohesion, etc.) to privacy compliance.
- Enterprises generate voluminous amounts of unstructured data (video, audio, image, social media, etc.) that has no immediate value but has potential value. Such raw, unstructured, uncurated data is usually loaded (untransformed) into a centralized data lake where data scientists can subsequently explore the data and find value from it. But this is heavy duty work on the part of the data scientists and as a talent group they are few in number.
- As data has traversed the data pipelines, and has been transformed and loaded a number of times, by the time it reaches its destination data store and is ready to be queried and analyzed, the data lacks sufficient freshness for many use cases. This is creating increasing demand for being able to query data at its source, in what is known as a data mesh architecture.
- Even as data pipelines have been effectively constructed, within enterprises there is an inherent mismatch between the data transformations conducted by the data engineers and the data format requirements of the business analysts. This is driving innovation in data products, data apps, and semantic layers, to enable analysts to work with higher level abstracts of the data (e.g., metrics, customized interfaces), to reduce compute time and also make them more productive.
Pipelines, Data Stores, & Compute
Below is a simplistic diagram showing the flow of data and compute of that data. The data pipelines are engineered to connect to source data and process that data. The processing may be in batches, micro-batches, or real-time, depending on the use case.
Large volumes of unstructured data with no immediate value would likely be processed in large batches, perhaps one or two times per day. More time sensitive data, such as that related to social media sentiment analysis and energy optimization, would be processed in micro-batches, perhaps a few times per hour. And highly time sensitive data, such as alerts related to cybersecurity, networks, and high-frequency trading, would be processed in real-time.
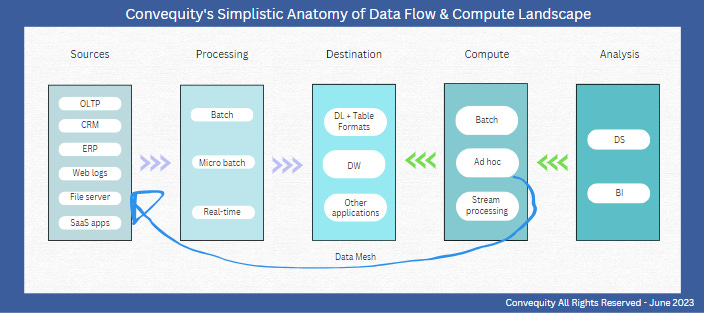
Once the data is processed (batch, micro, or in real-time), whether it has been also transformed or not, it will be loaded in a data lake (DL), a data warehouse (DW), and/or could be loaded as an input to another application. The technical terms for data moving from source, being processed, and then loading in the destination data store (DL or DW) are ETL and ELT. Respectively, they stand for Extract, Transform, & Load and Extract, Load, & Transform. Which of these is applied within the data pipeline depends on whether data is transformed before being loaded in the destination data store (DL or DW), or is transformed after it is loaded in the destination data store.
Historically, ETL was the dominant approach, but in recent years ELT has probably become more popular. This is because DW vendors like Snowflake, as well as third-party vendors like dbt, enable efficient data transformation once the data is inside the data warehouse. Likewise, table formats have been created for DLs, whereby they sit atop a DL and transform the raw, uncurated data into usable formats so that analysts can interact with the data. Therefore, doing ELT instead of ETL, all else being equal, reduces the number of locations the data needs to travel to by 1, because in essence the transformation is done inside the DW/DL, not at an external intermediate location. This obviously lowers costs for an enterprise with complex data pipelines.
Thus far, we can better understand why Snowflake and Databricks garner so much attention in regards to the Modern Data Stack. The DW and DL are the destination for processed data and the destination for analyst queries. In essence, they are at the heart of the MDS.
SNOW operates on the mid-to-right hand side of the above diagram. Historically, they served the BI analyst needing to make batch or ad hoc query workloads, but mostly the latter, and those queries are executed against the CDW.
Historically, Databricks served data scientists, but across a broader scope. They provide a managed service for the open-source Spark, which is a big data framework for processing, compute, and analysis of data enroute to, or stored in, the DL. And whereas SNOW has focused on ad hoc, Databricks has catered for batch workloads. However, both data management vendors are now aggressively expanding from their core areas of expertise. They both aim to serve data scientists and BI analysts and provide each type of compute workload (batch, ad hoc, stream).
Both have rearchitected their stack to facilitate their expansion plans. Databricks has created Delta Lake, which is an abstraction storage layer (labelled table format in the diagram) that sits atop the DL and transforms raw data into table formats, so that data can be efficiently analyzed. Combined, Databricks storage and compute layers form the Lakehouse. Snowflake has introduced native support for semi-structured and unstructured data that allows users to store raw data in the CDW and curate it later on ready for business analyst consumption. More recently, Snowflake has made significant progress in providing various native AI/ML tools for data scientists, so they can directly explore and analyze raw data inside of Snowflake.
In essence, Snowflake and Databricks have both expanded to incorporate the handling of structured and unstructured data but from different directions (Snowflake from structured to unstructured, and vice versa for Databricks). Snowflake has named themselves a Data Cloud and DataBricks has named themselves a Data Lakehouse.
Another key player within the MDS is Confluent. They provide a managed service for Kafka, which is an open-source distributed framework for building and managing data pipelines for event streaming. As mentioned earlier, sources of data are often consumed as inputs by other applications, as well as being ELT/ETL-ed into the DL/DW. In real-time processing this is referred to as event streaming, an event being any digital event such as a user clicking a subscribe button, or an IoT device sending a threshold alert.
In Kafka parlance, there are event producers (i.e., the original sources of data) and event consumers (the applications that need the events as input). And once engineered, Kafka works as the middleman or broker, and receives all events from the producers and then dispatches those to the relevant consumers, accordingly. This architecture removes the need for each producer and consumer to maintain multiple connections, hence taking strain off the enterprise’s resources.
Confluent’s value comes in as enterprises realize that engineering and maintaining Kafka internally without third-party vendor support is extremely challenging. In a large enterprise, there might be hundreds of data sources, which serve as inputs for tens of applications. And whether these applications are mission critical or not, the data pipelines need to be highly resilient and the data that feeds them must be always highly available with short recovery times should any disruption occur to a single data pipeline. To achieve this level of redundancy and availability requires highly distributed architecture able to deliver the required throughput for these events, many of which are time-sensitive. Kafka’s founders are the same team that went on to found Confluent, hence they have the expertise to generate huge value for enterprises using Kafka.
Key Players in the Modern Data Stack
Below we present Convequity’s Key Players in the MDS. The diagram shows the different layers of the stack and the key players and open-source technologies. We’ve attempted to illustrate the relationships between those open-source technologies and the vendors who provide managed services for them by having the vendor’s box encapsulate the open-source technology’s box. For example, Confluent’s box encapsulates Kafka’s box because the former is a vendor that provides a full managed service for Kafka.
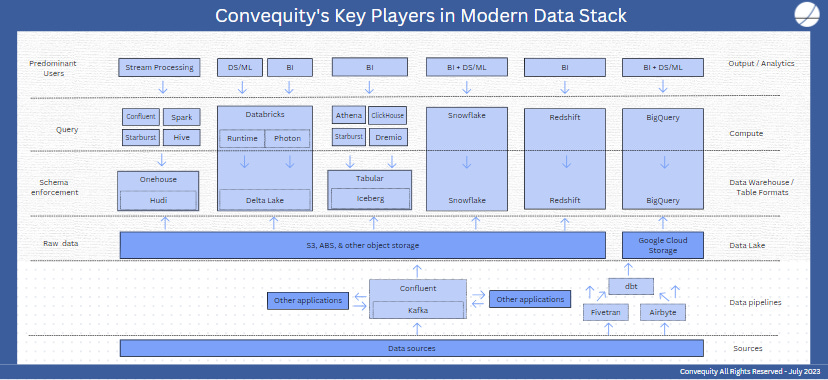
We’ll circle back to Snowflake and Databricks because they are at the heart of the MDS. Ultimately, the objective of both vendors is to transform, store, and organize any type of data in a way that is easily queryable for business analysts, data scientists, and any other type of user. Snowflake has this storage + compute all wrapped in a close-source Data Cloud, while Databricks is an open-core vendor, meaning they’ve built their storage + compute on top of the open-source Spark and call it the Lakehouse. The key advantage Snowflake has over Databricks is that they own the storage layer. This has given them opportunities such as:
- creating a marketplace for data sharing
- optimizing BI workloads
- enhancing security and governance
- creating vertical-specific clouds
- creating an application building layer underpinned by the storage layer
Snowflake also has strong competition from AWS’ Redshift and Google’s BigQuery. These are probably the most like-for-like rivals because they both own the storage and compute layers. These hyperscalers may be able to deliver 1-2x better performance than Snowflake but this is unlikely to sway customers away from Snowflake. Snowflake’s end-to-end user experience is unmatched and the other notable advantage is that Snowflake is multi-cloud.
Probably Snowflake’s biggest competitive threat comes from a number of different assortments of startups + open-source at the compute and the storage layers. For instance, an enterprise could decide to choose Starburst or Dremio for their compute engine and a Tabular-managed (or a self-managed) service for Iceberg for their storage layer. In such an arrangement, an enterprise could save costs by doing some aspects themselves via open-source while getting vendor support in another aspect. And as the enterprise's data would be stored in open formats (not proprietary formats like Snowflake's), it helps thm avoid vendor lock-in. The disadvantage, however, is that such a combo will unlikely match the superior end-to-end user experience of using Snowflake. Therefore, we might see the market evolve whereby cost-conscious enterprises, or enterprises with substantial engineering resources, will opt for a combo like Starburst (for compute) and self-managed Iceberg (for storage), whereas less cost-conscious enterprises, or those with fewer engineering resources, will opt for Snowflake.
The advantage of using Starburst is that users can query data at its source in addition to querying Iceberg tables. In effect, this removes the need to ETL/ELT the data to a centralized data store, saving substantial costs in data transfers and gives users the opportunity to access fresher data.
Emerging developments within MDS
There are a number of new technologies and approaches emerging that seek to address the internal frictions experienced between departmental workers (e.g., in marketing, finance, etc.), data engineers, data scientists, and business analysts within an enterprise. These frictions are born as a result of all stakeholders requiring usage of the data, but at the same time each stakeholder type maintains a different relationship with the data, leading to them needing a different representation of the data.
Data Products
Data Product is a concept whereby data is presented/available in a way that is immediately useful. An apt analogy would be to use sand, glass, and a vase for holding flowers. Sand (raw silica to be precise) is the raw material and is processed to make glass; then glass can be processed to make a vase. In the current MDS, sand is similar to raw, uncurated data located in the DL and the glass is similar to data residing in the DW or in table formats atop the DL. For a stakeholder to query and fetch the data they need, they would probably need to make a number of queries and run various filters and joins across datasets in order to get the representation of the data they require. The data product in this analogy is the vase. Hence, as a vase is immediately useful, that is, you can immediately add water and put the flowers in it, a data product is immediately useful too, and might consist of a table of data showing all the key metrics important to the enterprise's marketing endeavours.
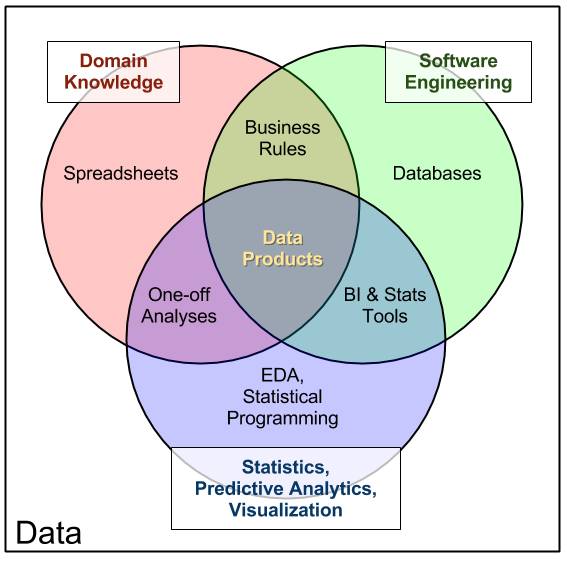
https://www.datacommunitydc.org/blog/2013/09/the-data-products-venn-diagram
The idea is to have departments like marketing, operations, sales, etc., in charge of preparing these data products associated with their domains. They are responsible for preparing and processing the data into a data product which is available to those stakeholders who need to use it. As implied in the name 'product', they are responsible for the quality of the data product, the availability, costs, etc., just like it is a tangible product. Other aspects for the domain team to consider and implement, with assistance from the data engineer, include: 1) raw data ingestion, 2) data transformations, 3) federated policies for building data products (e.g., data products must always be presented in a Parquet file in AWS S3), and 4) a data contract to establish the expected quality of the data and how it will be used etc.
Data products are a major component of the rising data mesh architecture. As per the description, you might have noted that this approach is more decentralized than centralized because the data preparation and general responsibility is handed to domain teams, not handled centrally by the data engineering team. Having decentralized data products available for all users across the enterprise resembles a mesh-like architecture. The leading startups like Starburst, Clickhouse, and Dremio are supporting data product operations, so is Snowflake and Databricks.
Data Apps
A data app serves a similar purpose to a data product, which is it abstracts away the underlying complexities of managing data that is not already highly curated. However, they are more than a data product in the sense that the user enjoys a UI and a tightly integrated interactive experience as they explore and find answers within large datasets. Data apps are designed to handle data-intensive operations whereby the user needs to efficiently sift through large datasets. They have similar characteristics to traditional web applications, but are designed to work with voluminous data and to serve clear answers to specific questions. Google Analytics is a good example of a data app.
There are many more consumer-facing data, or data-driven apps, like Google Analytics; however, recently they have gained attention for internal and B2B relationships. For instance, traditionally a data scientist might find it difficult to make large datasets easy to explore and find answers for business analysts. If she/he can design a data app customized for the business analyst use case, then this would be much more productive for the business.
Snowflake is leading this data app trend thanks to its tight in-house integration between the storage and compute layer, and also thanks to its swift expansion to cater for data scientists with its Snowpark platform, where data engineers and data scientists can write custom applications in the programming language of their choice (Python, Scala, Java, etc.).
Semantic Layer
The emergence of the semantic layer aims to address similar issues to what data products and data apps address. The DW stores curated data but not highly curated data in the sense that the data elements are stored in rows and columns across many tables, meaning analysts need to conduct various data manipulations before they have fully retrieved the representation of data they are seeking. Data products, data apps, and the semantic layer aim to further curate the data so that less time and compute is spent on performing this intensive data manipulation for each query (e.g., filter, pivot, sort, join).
Specifically in regards to the semantic layer, the idea is to create standardized metrics and a standard vocabulary for these metrics, and to add contextualized information to these metrics. Right now, different BI reporting tools may make the same query but get different answers. This is because there are various ways to manipulate the data to retrieve an answer or a view of data, and this leads to inconsistencies and makes it challenging for BI tools to effectively communicate with one another. Therefore, the semantic layer strives to further curate the data into standardized metrics and help provide a single source of truth, or a single source of data representation for a given query.
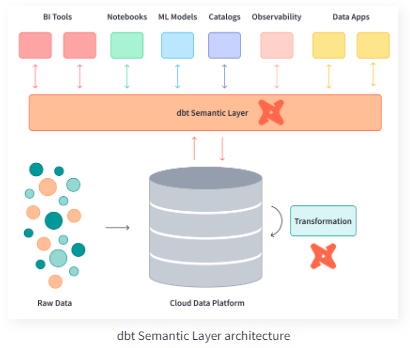
https://docs.getdbt.com/docs/use-dbt-semantic-layer/dbt-semantic-layer
Dbt Labs are making progress with delivering semantic layers for enterprise customers, which although is higher up the MDS than where they originate (as per the second diagram above, traditionally dbt is used to transform data bound for the DW, or transform it once inside the DW), is playing to their transformation strengths. Snowflake and Databricks are developing partnerships to enable the semantic layer and we expect there will be lots more innovation to come.
HTAP
Hybrid Transactional Analytical Processing, or HTAP, is the final emerging development we'll mention. It isn't exactly a new idea because it has been tried in the past by Oracle and others with limited success. Essentially, it involves the integration of Online Transactional Processing (OLTP) and Online Analytical Processing (OLAP). OLTP, a database responsible for executing vital business transaction tasks like inserting, updating, and deleting, especially in financial contexts, is engineered for efficiency and simplicity. This is crucial as it needs to handle significant data in real-time. As indicated in the first diagram showing the flow of data and compute, OLTP often serves as a data source for OLAP, a term primarily associated with DW.
Traditionally, the data from OLTP is reformatted from row to columnar structures and standardized for OLAP's analytical tasks. However, Snowflake has reimagined the simultaneous application of both OLTP and OLAP, resulting in Hybrid Transactional Analytical Processing (HTAP). This innovation will enhance data processing speed and lower costs by reducing the load on the data transformation pipeline. If Snowflake succeeds in preserving original OLTP data for analytical use, it will significantly broaden its TAM beyond its primary cloud-based DW. This would be a significant achievement since this area is the cornerstone of Oracle's multi-billion-dollar enterprise.
Readers who would like further information about the Modern Data Stack and its key players, feel free to book a 30 minute call with us to discuss.


Comments ()