
Lumentum Holdings: The Optical Engine Behind the AI Data-Center Revolution

Summary
- Record 1Q26: $533.8m revenue (+58% YoY) with next-quarter guide $630–$670m; cloud/AI now >60% of mix, beating the $600m/quarter goal early.
- Growth is structural as hyperscalers shift from copper scale-up to optical scale-out, accelerating 800G/1.6T transceiver demand.
- LITE’s leadership in 200G-per-lane EMLs and move up the stack (cloud modules, OCS, CPO) deepens hyperscaler attach and raises pricing power.
- Vertical integration (CloudLight) and richer mix target mid-30s → low-40s gross margins and potential >15% FCF margins as systems ramp.
- Market is pricing in mid-20s growth beyond FY26, stretching the valuation. Though this company could experience major reacceleration like we've previously seen with NVIDIA and are currently seeing with Palantir.
1Q26 Quarter Results - Just Out
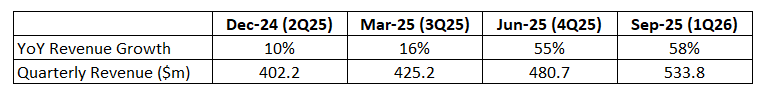
Source: Seeking Alpha
LITE reported record quarterly revenue of $533.8m, up 58% year over year and well ahead of expectations — its fastest growth in a decade. Guidance for next quarter sits between $630–$670m (midpoint ~$650m - an annualized QoQ growth of 120%), meaning the company will surpass its $600m-per-quarter target two quarters earlier than originally planned. Cloud and AI infrastructure now account for over 60% of revenue, with strong demand for next-generation laser components driving both higher utilization and margin expansion.
The massive step-change in growth reflects a structural transformation rather than a short-term spike. Over the past year, YoY revenue growth accelerated from 10% in Dec-24 to 16% in Mar-25, then surged to 55% in Jun-25 and 58% in Sep-25 — tracking directly with the hyperscaler-driven boom in optical networking. Earlier this year, industry forecasts called for roughly 10 million 1.6T optical transceivers to ship in CY26; by mid-year that estimate doubled to 20 million, and it now stands near 35 million units. These cutting-edge transceivers, powered by LITE’s core laser components, are being deployed to support more efficient AI clusters. The “DeepSeek moment” in 1H25 — when the industry's vision shifted from scale-up to scale-out architectures — has brought forward the optical decade, and LITE is one of its earliest and clearest beneficiaries.
Intro - DeepSeek's Influence on Lumentum
A silent architectural shift is reshaping AI infrastructure — one that determines how fast intelligence itself can scale. For years, AI training efficiency depended on scale-up designs: tightly coupled GPUs communicating through copper-based NVLink inside a single server. This “intra-node” domain, exemplified by NVIDIA’s NVL8 and NVL72 architectures, maximized bandwidth within a box but hit hard physical limits beyond it - i.e., inter-node (scale-out). Electrical interconnects degrade rapidly at distances over a few meters — not just from heat and latency, but from exponentially rising error rates as copper cables approach their physical size limits, making inter-node, high-speed transmission increasingly unviable.
In 1H25, that ceiling cracked. DeepSeek’s open-sourced P/D inference cluster and Huawei’s all-optical CM384 pod demonstrated that scale-out — connecting servers or racks across a data center — can now rival or surpass traditional scale-up in both cost and performance. Scale-out communication today primarily runs over Ethernet, which remains the industry standard, influenced by hyperscalers valuing openness and vendor flexibility. Ethernet allows them to maintain competition among switch suppliers such as Broadcom and Marvell, and preserves bargaining power in negotiations with NVIDIA.
By contrast, InfiniBand, acquired through NVIDIA’s 2019 purchase of Mellanox, is a proprietary alternative optimized for ultra-low latency and high throughput — but one that ties customers deeper into the NVIDIA ecosystem, which many customers don't like. What’s changing now is not the networking protocol itself but the physical layer: copper is being replaced by optical links. DeepSeek’s distributed inference framework showed that by rearchitecting workloads — and leveraging Huawei’s optics-based scale-out fabric — clusters of hundreds of GPUs can operate efficiently across nodes without relying on NVIDIA’s copper-bound, expensive, and increasingly constrained NVLink topologies. Meanwhile, Huawei’s all-optical superpods, linking hundreds and soon thousands of Ascend chips entirely through light, revealed that photonics is not just a performance enabler but a strategic weapon in the AI-infrastructure race to challenge NVIDIA’s dominance despite weaker single-chip performance.
The shift has also awakened demand for optics within scale-up itself. Google has announced plans to make its TPU clusters fully optical within the next two years — proof that even intra-server and rack-level connections are migrating to light as bandwidth and thermal limits close in. NVIDIA, meanwhile, has acknowledged the growing pressure from these optical-first architectures through its recent Enfabrica acquisition. Enfabrica isn’t an optical company per se; its networking silicon is designed to improve bandwidth efficiency and reduce bottlenecks inside scale-up systems. But the move underscores NVIDIA’s recognition that its current copper-based NVLink approach is being outpaced by optical alternatives pioneered elsewhere. We see this as Jensen Huang’s attempt to, perhaps stubbornly, reinforce NVIDIA’s scale-up dominance without fully conceding that optics has already won the physics argument.
Together, these breakthroughs have forced NVIDIA’s hand: the next frontier of scaling will be optical. Data movement, not compute, is now the bottleneck — and the only medium capable of breaking that bottleneck is light. That’s why the transition from electrical to optical signaling inside the data center has accelerated years ahead of expectations, creating a generational opportunity for suppliers of the optical engines that make it possible.
Lumentum (LITE) sits squarely at the center of this inflection. Its growth reacceleration over the past two quarters aligns closely with the DeepSeek and Huawei architectural innovations that have pulled long-term optical adoption forward. It also benefits from the proliferation of custom ASICs — such as Broadcom’s TPU-class silicon — that rely on all-optical networks to connect both scale-up and scale-out domains. As the leading manufacturer of Electro-Absorption Modulated Lasers (EMLs) and high-speed optical components that convert electrical data into light, LITE is poised to become the indispensable enabler of AI scale-out and the coming convergence of optical compute fabrics.
From Electrons to Photons
Inside every AI data center, optical transceivers act as the gateways between chips — converting electrons into photons on egress (outbound) and photons back into electrons on ingress (inbound). This conversion enables GPUs, switches, and routers to communicate optically at terabit speeds, while the fiber links between transceivers actually carry the light signals. Together, they form the neural pathways of AI compute clusters, moving vast amounts of data with nanosecond precision and minimal power loss over longer distances than traditional copper cables can deliver.
Today, most large-scale data centers still rely on 400G transceivers, which represent the mainstream deployment standard. The industry, however, is rapidly transitioning toward 800G and eventually 1.6T transceivers to meet the escalating bandwidth needs of AI workloads.
Inside every high-speed optical transceiver, the Electro-Absorption Modulated Laser (EML) acts as the core engine — converting electrical data into modulated light signals that travel through fiber. Each EML lane transmits a defined data rate, and by combining multiple lanes, transceiver modules achieve their overall throughput.
Sidenote: As we have covered in the SysMoore-related reports, to deliver another 1000x gains in performance, the industry needs to scale, not just on the chip level, but at the system level which requires high-speed connections between multiple servers far away from each other.
Today, most 400G transceivers use 100 Gbps-per-lane EMLs, but Lumentum leads the next generation with 200 Gbps-per-lane designs powering 800G and 1.6T optics. It remains the only supplier shipping these 200 Gbps/lane EMLs at scale. While its own transceiver-module business (where LITE makes not just the EML but the entire transceiver), gained through the CloudLight acquisition, is still in early ramp, demand for Lumentum’s EMLs from external transceiver module makers is already accelerating rapidly.
These optical engines are indispensable to AI architectures such as NVIDIA’s GB200 NVL72 and GOOG's TPUv7, which require low-latency, high-bandwidth optical links to connect thousands of GPUs. Without such light-based interconnects, AI compute would hit a hard ceiling imposed by copper’s electrical limits.
This is the new paradigm: AI compute now scales only as fast as data can move between chips — and that data moves on light.



