AI Value Chain Bottlenecks: Mapping Pricing Power and Investment Opportunity (Pt.1)
Summary
- Supply-demand imbalances ebb and flow across the AI value chain — as one bottleneck eases, pricing power and pressure shift to other segments rather than resolving in isolation.
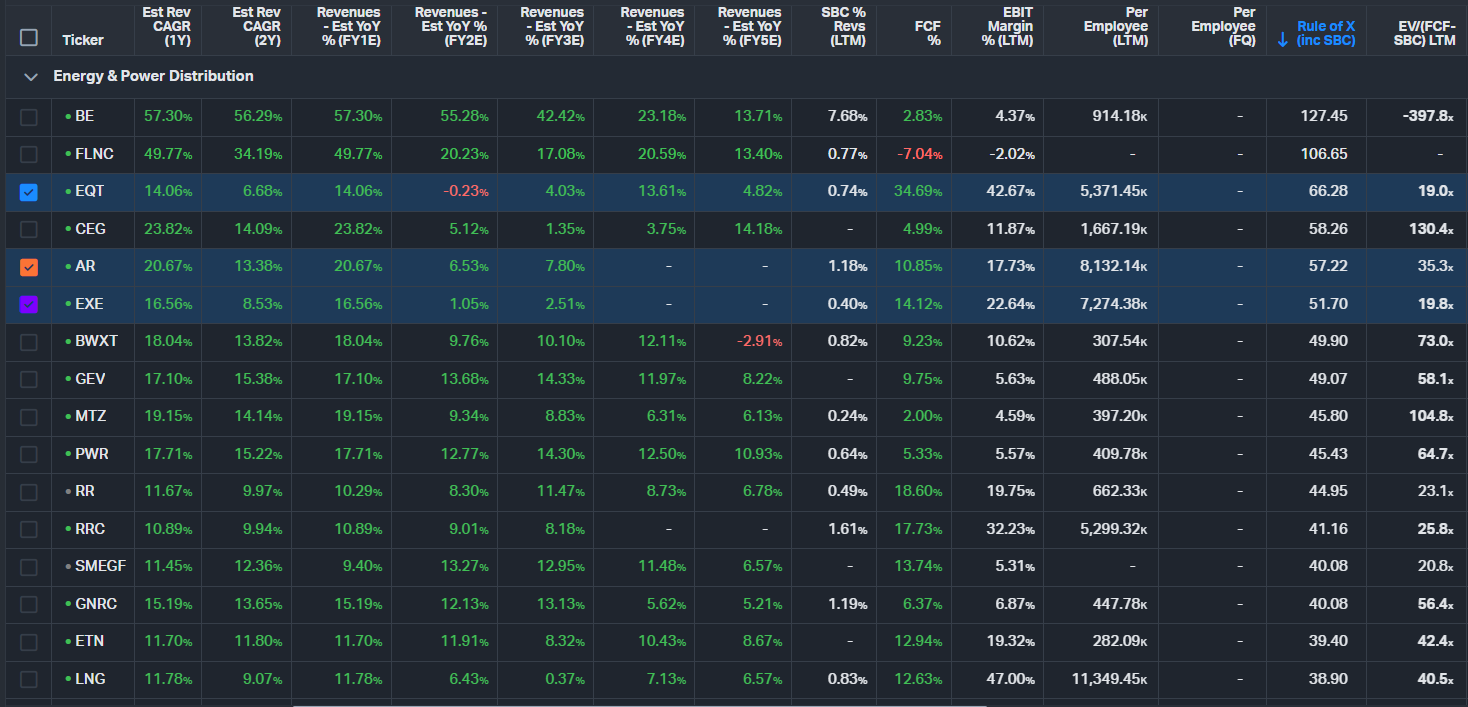
- Energy & Power Distribution segment is still a bottleneck, but natural gas and Bitcoin miner conversions are bridging near-term supply, while the Data Centre segment remains firmly bottlenecked.
- A subsegment-tailored Rule of X framework adjusts growth coefficients for cost structure, risk, and operational maturity to screen for mispriced companies across the value chain.
- Converted Bitcoin miners hold a structural speed advantage over traditional colocation providers, bringing AI-ready capacity online in months rather than the years greenfield builds require.
- The optical interconnect layer — constrained by indium phosphide scarcity, the shift to 3.2T modules, and scale-across demand — may gate the AI buildout's pace more than energy or servers.
Note: this report is an overview of the AI value chain landscape. For subscribers and clients who want more details on specific segments and/or stocks, please reach out to service@convequity.com. Alternatively, subscribers will receive segment and stock-specific reports in the coming weeks.
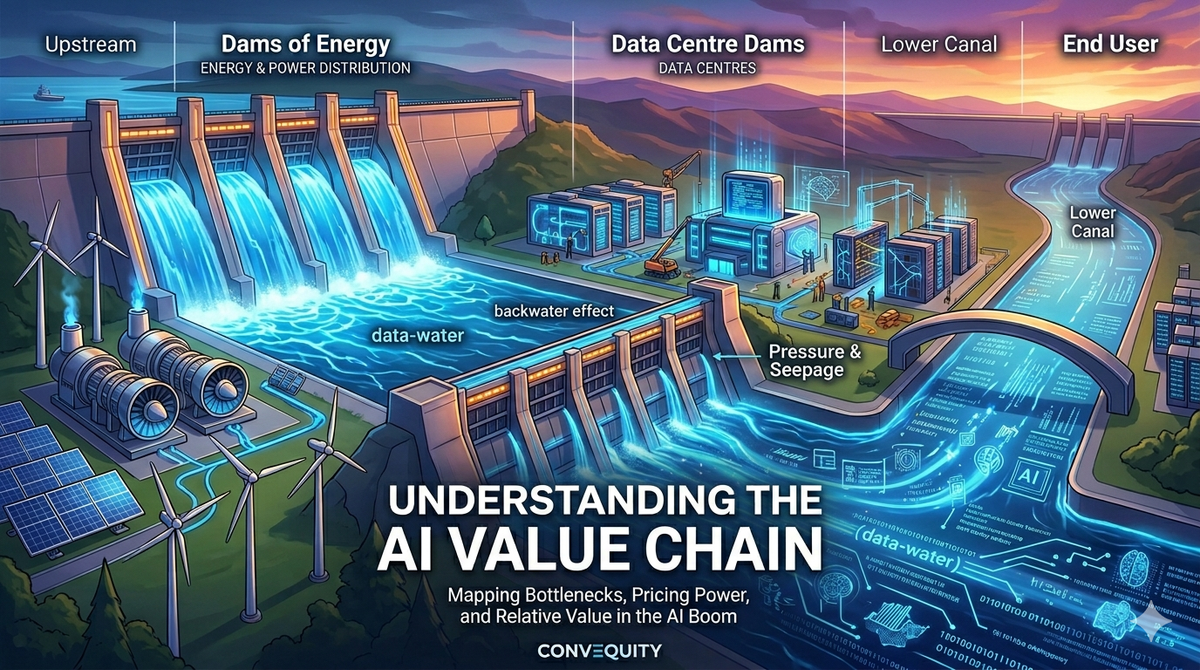
The Canal and Dams Analogy
At Convequity, the way we think about AI investment opportunities — and how we advise our clients — is through the analogy of a canal divided into segments by a series of dams.
Imagine the AI value chain, from energy generation through to the end user, as a long canal. Demand is rampant, but the supply side is extremely capital-intensive with long lead times. This mismatch creates demand-supply imbalances that appear at different times and with different magnitudes across the chain. The dams represent these bottlenecks.
Right now, the most acute bottleneck sits at the uppermost segment: Energy & Power Distribution. Over the past year this dam has begun to lift — new supply has been gradually coming online — but it is far from fully open, and the water level remains high, keeping prices elevated. When it begins to open more and supply flows more freely, the water level in this segment will fall toward balance. But as the water moves downstream it hits the next closed dam — in our framework, Data Centres — and the cycle repeats: rising water, fresh imbalances, another round of price surges. When that segment's suppliers finally catch up, the bottleneck and its pricing power shift further downstream again.
Real-world supply chains, of course, are far messier than a neat sequence of dams opening one after another. Major data centre backlogs are already building while the energy bottlenecks are very slowly unwinding but still substantial. The canal analogy is not meant as a literal timeline; its value is as a conceptual framework for how the centre of gravity of imbalance and pricing power ebbs and flows along the value chain, rather than segments rising and falling in isolation. The two spillover mechanisms below are what make this interconnectedness explicit.
In the upstream direction, there is the backwater effect. With the upstream dam already open, water piles up against the closed downstream dam and pushes backward — a sloping rise that is highest at the bottleneck and tapers off with distance. In the value chain, this explains why a shortage in data centre capacity can keep demand and prices for energy components artificially elevated even after new energy supply has unlocked — lower than if the energy segment's own dam were still closed, but above a fully balanced level.
In the downstream direction, this creates what’s known as pressure and seepage. Even with the dam closed, the sheer pressure of the rising water forces subtle “leaks” past the dam into the next segment. This appears as early, softer price signals and demand seepage that reach downstream players before the bottleneck fully opens.
Right now, we’re seeing this play out clearly across the chain. The dam for Energy & Power Distribution is roughly 1/3 open — slowly unlocking new MW and GW supply for AI data centres (something we’ll dive into later). Meanwhile, the Data Centre dam remains firmly closed, as evidenced by the massive order backlogs building in colocation, power, cooling, networking, and racks. This closed dam is creating strong adjacent pressures: pushing backward through the backwater effect to keep energy prices and demand elevated upstream, while forcing seepage downstream into semiconductors — the chips, memory, and specialized components that deliver the actual compute and memory for AI. Memory itself is already showing signs of tightening, though still less severely than many core Data Centre components.
The AI Value Chain Framework
There are many ways to segment the AI value chain. Here is the first conceptual framework we created a few weeks ago. It served just as a starting point for explicitly visualising the value chain and key players involved in each segment.
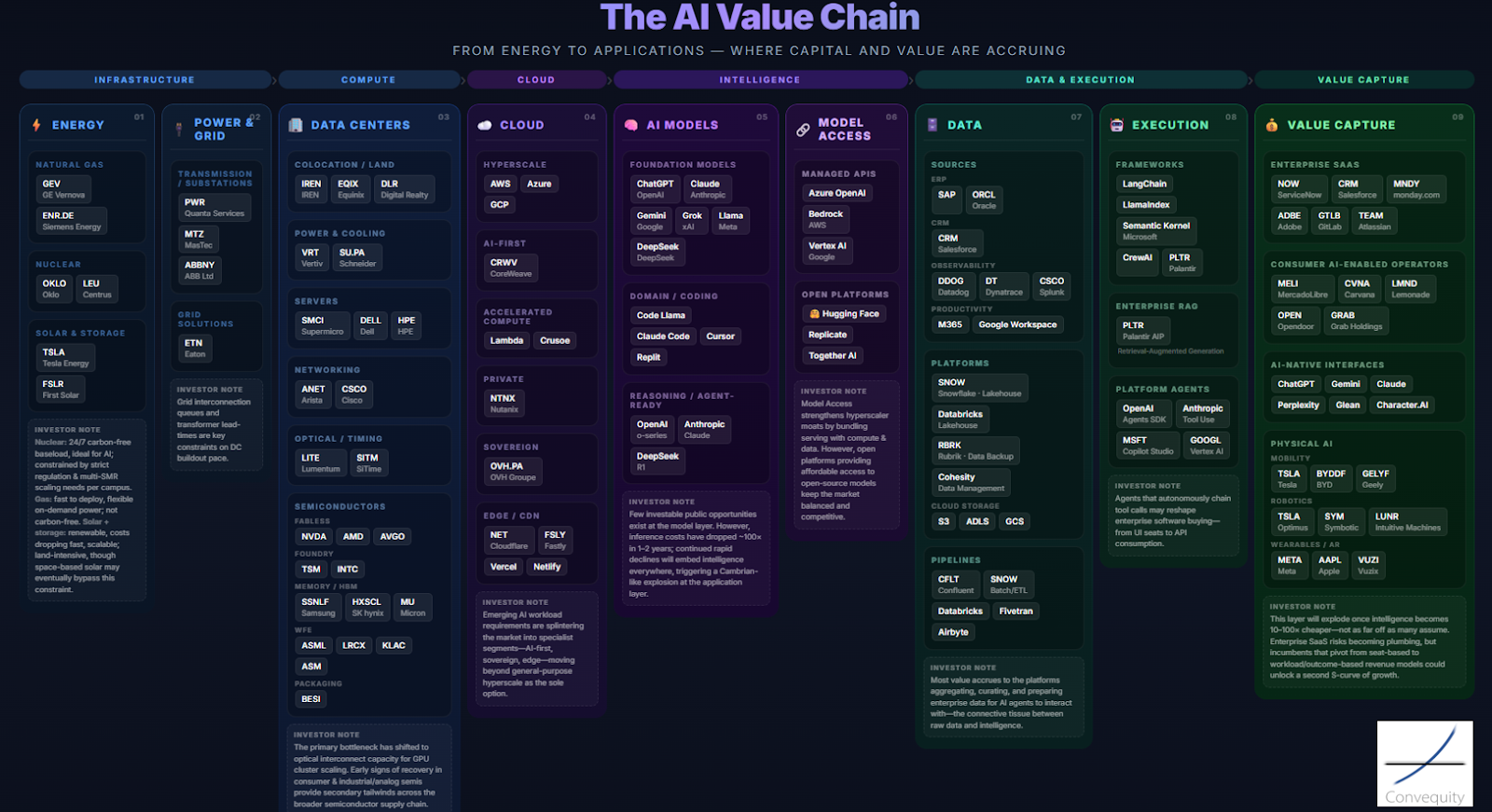
Source: Convequity
However, when we helped a client fund manager with portfolio construction, we felt that we needed to adapt the framework, so each segment was more distinct and clear. For investors, the segmentation needs to strike a balance: granular enough to surface which areas look attractive, but broad enough that adjacent segments carry meaningfully distinct exposures and demand-supply dynamics rather than moving in lockstep. Our updated segmentation is shown here:
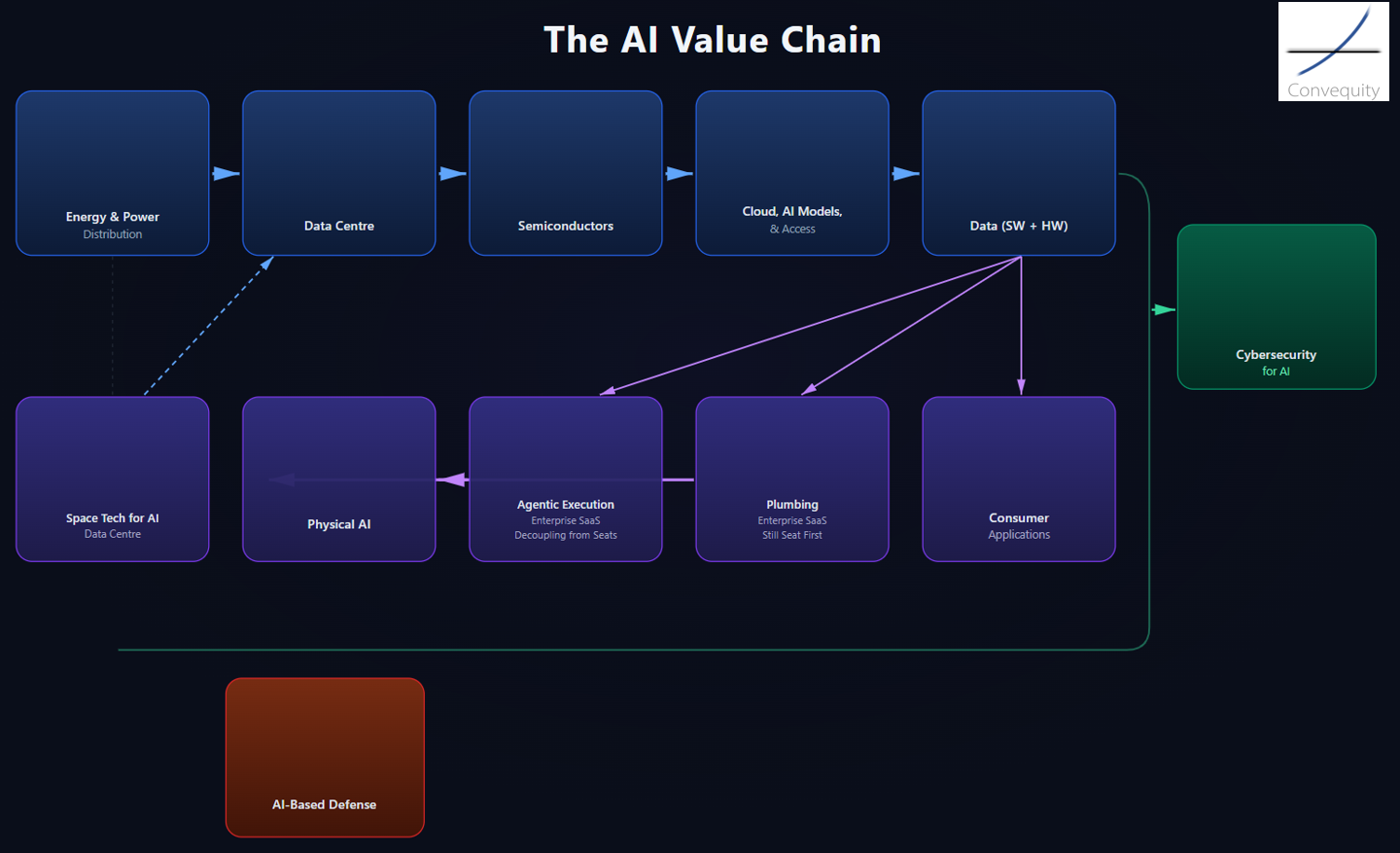
Source: Convequity
The goal is to group companies that share similar market dynamics, industry exposures, and business models into the same segment. Furthermore, we've created subsegments within each segment because there are cases where a subsegment, like Networking & Optical, has notably different dynamics to other areas within the Data Centre segment:
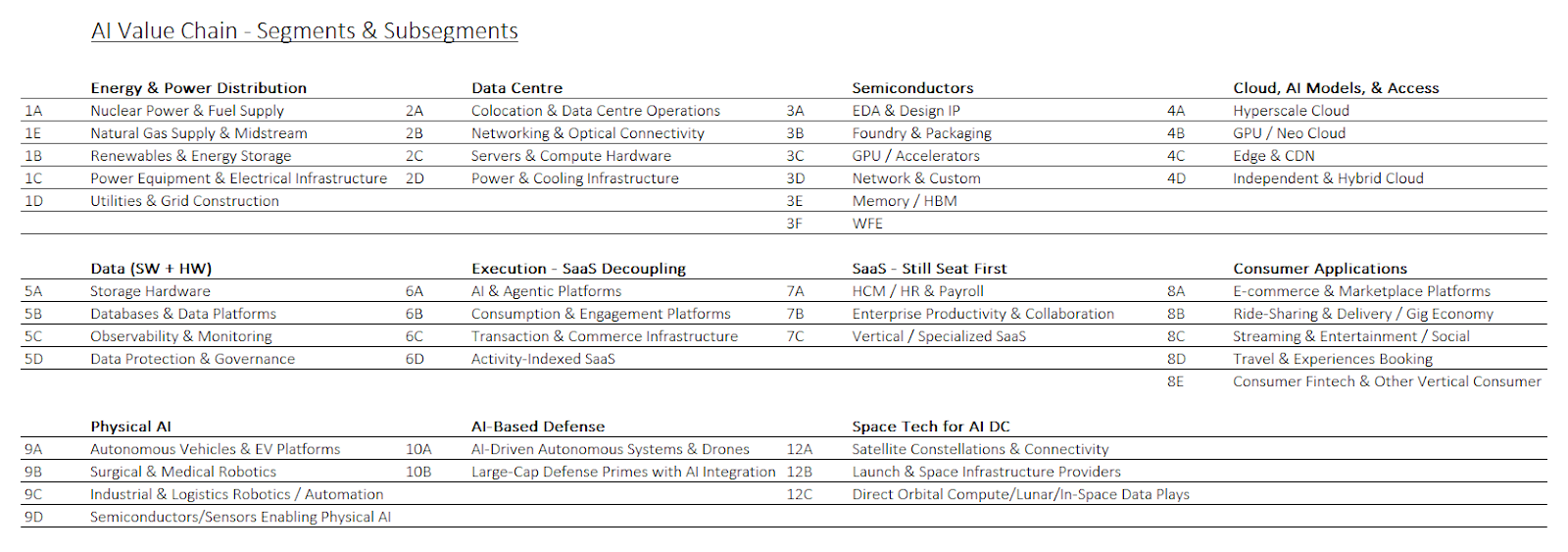
This allows us to compare relative value between companies within segments and subsegments, and to compare median multiples across segments/subsegments to identify which look expensive and which do not — cross-referenced with knowledge of order backlogs and other supply chain dynamics to assess whether elevated multiples in a given segment are justified.
For this analysis we use our preferred metric, the Rule of X, and our preferred multiple, EV/(FCF–SBC). We calculate the Rule of X for every stock across the value chain, then rank them against their corresponding multiples as a screen for low-hanging fruit — instances where forward financial performance may not be properly priced by the market. Within each segment, we further categorize stocks into subsegments (as shown above), each receiving a tailored Rule of X. The rationale for this tailoring is explained below.
The standard Rule of X is an adaptation of the Rule of 40. Bessemer Ventures, after studying investor returns in SaaS, found that investors value growth 2.3× more than profit (median), giving the formula:
Rule of X = (NTM Rev Growth × 2.3) + LTM FCF Margin
We adapt this further by incorporating stock-based compensation as a percentage of revenue:
Rule of X = (NTM Rev Growth × 2.3) + (FCF Margin – SBC%)
However, applying a uniform 2.3× growth coefficient across all company types would be naïve. A dollar of revenue growth is not worth the same across businesses with fundamentally different cost structures. This is visible at the gross margin level alone: a dollar of growth for Datadog at roughly 75% gross margin is worth far more than a dollar for Supermicro at roughly 15%. If both companies had identical forward growth expectations and stable gross margins, you would expect the gap in their Gross Profit multiples to approximate the ratio of their gross margins — roughly 5×. In practice, DDOG's NTM EV/GP is 12.5x × versus SMCI's 6.4×, with the gap compressed by SMCI's 89% NTM growth expectation against DDOG's 20%. The underlying point is that Bessemer's 2.3× was derived from SaaS companies carrying 70–90% gross margins and cannot be applied wholesale to subsegments with structurally different economics.
What we ultimately want to capture is how investors value the next incremental dollar of revenue, not a dollar already embedded in the run rate. Incremental dollars are valued through the incremental profit they generate. For each subsegment, we estimate the incremental operating margin by assessing the split between variable and fixed costs across both COGS and operating expenses. In theory, the incremental operating margin is 1 – v, where v is the variable cost ratio. A subsegment with 40% variable costs would have a theoretical incremental margin of 60%, meaning that the higher the fixed-cost base, the more valuable each incremental growth dollar becomes.
We then adjust for risk. Value from an investor's perspective is always discounted for the riskiness of the business, so we divide the incremental margin by a subsegment-appropriate WACC. This produces a raw growth coefficient.
Finally, we apply a realism discount. A theoretical incremental margin of 60% rarely means that 60 cents of every growth dollar falls cleanly to operating profit. In practice, some portion is absorbed by reinvestment — new hires, capacity buildout, capitalising on market conditions — or lost to inefficiency during rapid scaling. We therefore apply an operating leverage adjustment factor of between 0.4 and 0.5 to the raw coefficient. Established and mature subsegments with long-standing operational expertise — colocation in the Data Centre segment or foundry and packaging in the Semiconductor segment — receive a factor closer to 0.5, reflecting higher confidence that incremental margins will be realised in practice. Newer or more operationally volatile subsegments, such as Neo Clouds, receive a factor closer to 0.4, reflecting greater uncertainty around how much of the theoretical margin actually materialises.
The end result is a growth coefficient specific to each subsegment's cost structure, risk profile, and operational maturity, which replaces the generic 2.3× in the Rule of X formula.
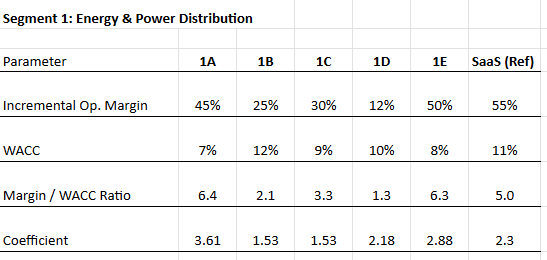
Source: Convequity
When we then cross-check each company's tailored Rule of X against its EV/(FCF–SBC) multiple, relative value becomes significantly clearer. Two companies might both trade at 40× and both post a standard Rule of 40 of 60. But after applying this process, one may carry a tailored Rule of X of 90 while the other sits at 50 — making the former materially more attractive on a risk- and quality-adjusted basis.
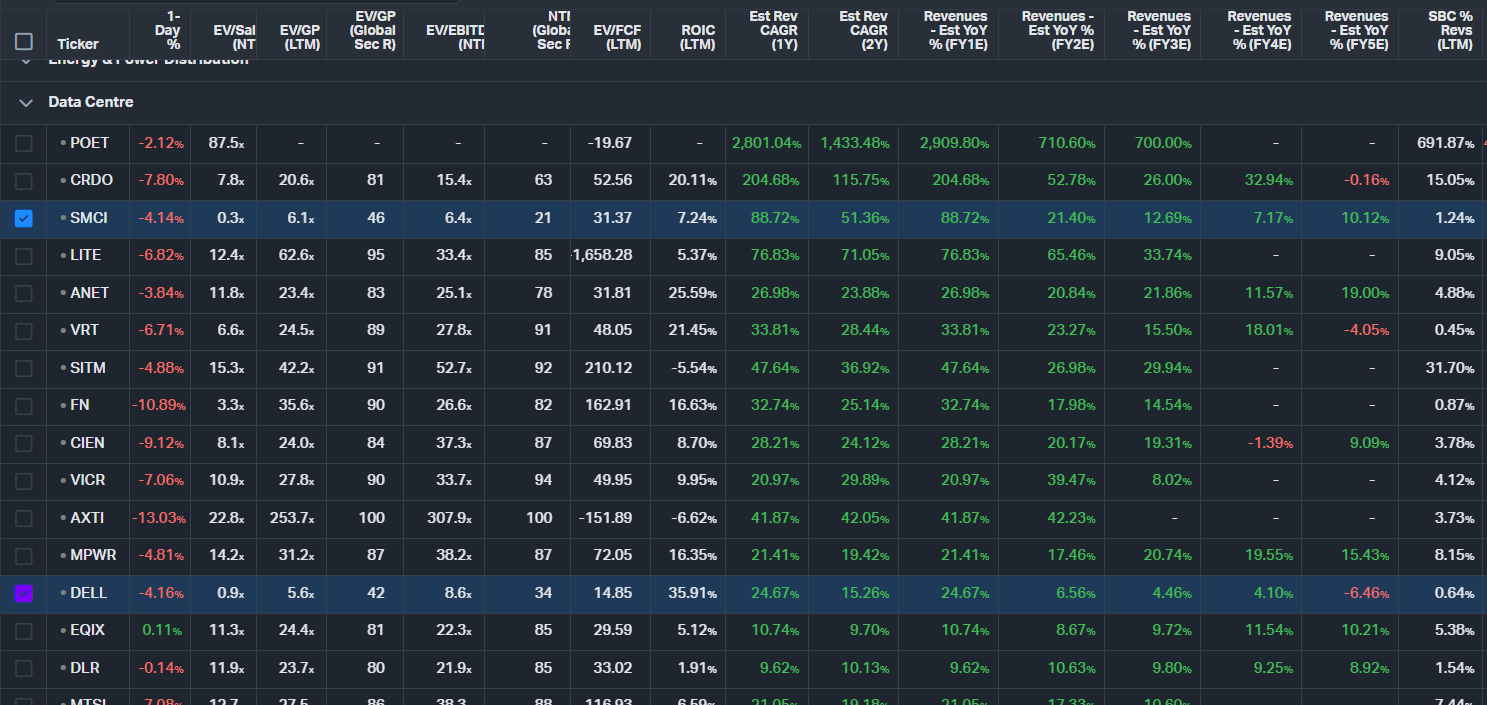
The following table shows the Rule of X ranking for Semiconductor subsegments. The companies highlighted in yellow are simply stocks with a relatively low multiple compared to their Rule of X. Note: we've ranked by Rule of X at both the segment level and the subsegment level. Here we show the subsegment level ranking.
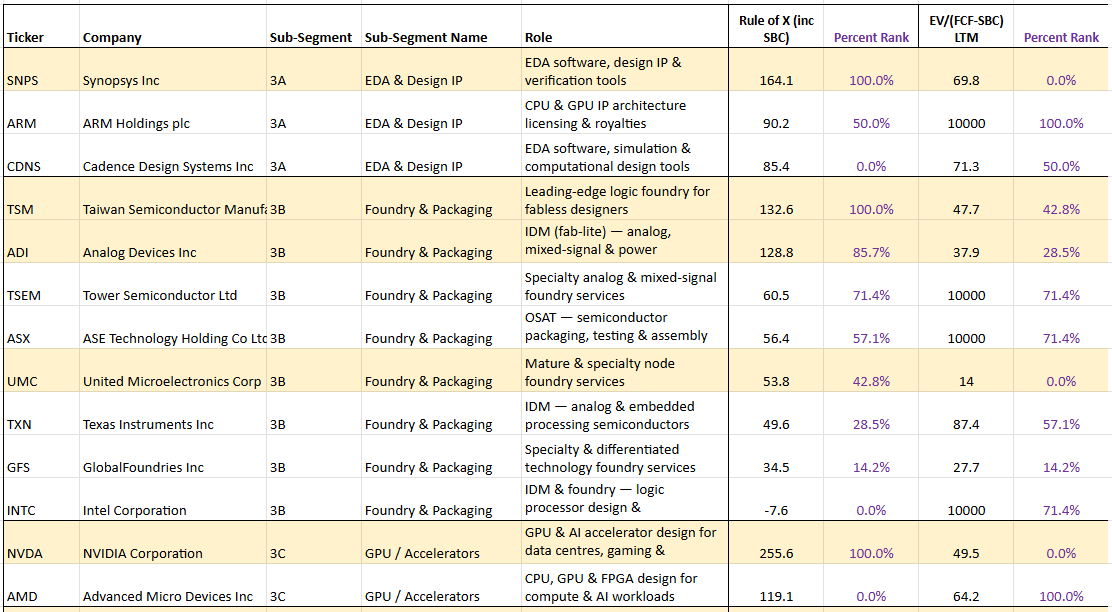
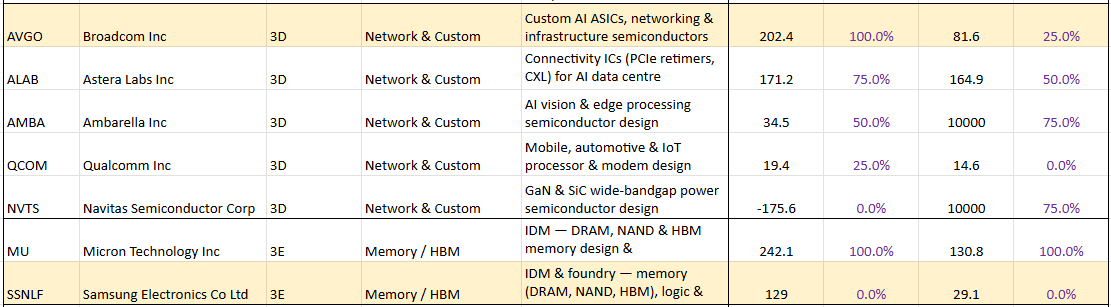
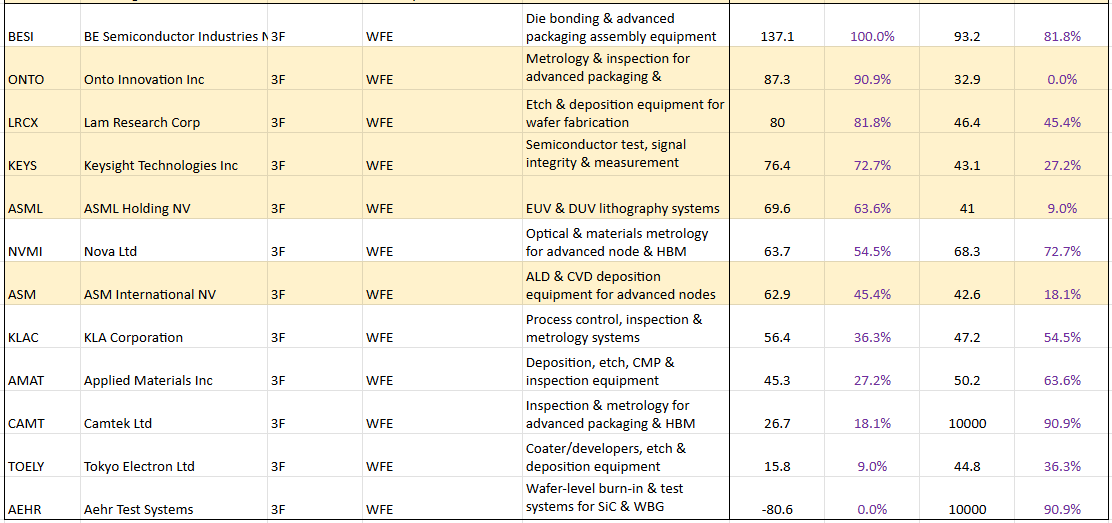
Source: Convequity
It's important to remember that this is simply a screen. After diving into any of these highlighted companies, it may become clear that there is a reason for the market pricing them at relatively low multiples compared to their Rule of X.
Once we have the Rule of X rankings at the segment level, we calculate the median Rule of X and the median multiple for each segment. The two segments that stand out are "Semiconductors" and "[Agentic] Execution - SaaS Decoupling from Seats", as these two segments have a relatively low median EV/(FCF-SBC) when considering their median Rule of X.
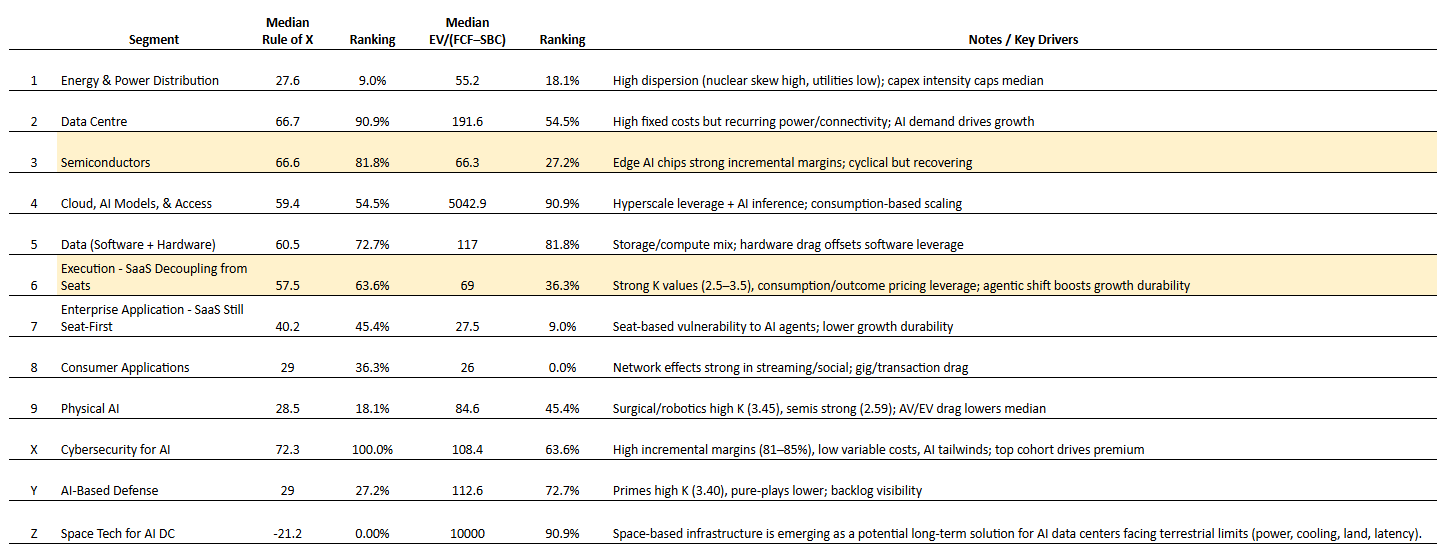
Source: Convequity
Now at a high level we'll discuss each segment and how we're thinking about investment opportunities.
Energy Distribution & Power
When ChatGPT dropped in late 2022, the hyperscalers kicked off a massive capex cycle to build out AI-first data centres. They quickly realised it wasn’t just about GPUs and facilities — they needed to pour serious money into the infrastructure required to deliver the massive amounts of power those data centres would consume.
The explosion in energy demand against limited supply created the first major bottleneck and demand-supply imbalance in the AI value chain. It became a serious constraint from 2024 through 2025/26. The three main energy sources for satisfying the AI demand are nuclear, renewables, and natural gas.
Initially, nuclear energy emerged as the hottest and most sought-after option thanks to its carbon-free, reliable 24/7 baseload power — exactly what always-on AI infrastructure needs. Excitement around nuclear surged further when the Trump Administration took office in early 2025 and delivered strong pro-nuclear rhetoric, followed by concrete action. In May 2025, Trump signed several executive orders directing a major overhaul of the Nuclear Regulatory Commission (NRC), including streamlining licensing to target 18-month approvals for new reactors, reforming regulations, and reducing barriers to deployment. These moves, combined with efforts to ease NEPA environmental reviews, signalled a clear push to accelerate new nuclear supply and unlock the GW-scale capacity hyperscalers desperately need. As a result, stocks related to nuclear energy - OKLO, LEU, RR, CEG, and others - performed strongly before peaking in 2H25.
By late 2025 and into 2026 the nuclear hype cooled noticeably. Deployment timelines proved stubbornly long — most new reactors and SMRs won’t deliver meaningful GW-scale supply until the 2030s, far too slow for the immediate AI data centre crunch. At the same time, as hyperscaler campus designs scaled from hundreds of megawatts to multiple gigawatts, SMRs — typically designed in the 50–300 MW range per module — began to look insufficient as a primary power solution for the largest facilities, undermining one of the key narratives that had fuelled the sector's rally. Eventually, this might become a minor issue because you can simply add more SMRs, but there would be more complexity in managing a fleet of SMRs.
On the regulatory side, the ambitious NRC reforms and NEPA easing moved slower than hoped amid bureaucracy and implementation gaps. Meanwhile, nuclear stocks pulled back sharply as investors took profits on overvalued pre-revenue names and faced a lack of near-term revenue catalysts.
Due to these nuclear hurdles, attention quickly swung back toward renewables — especially solar. After all, solar is carbon-free, and when paired with battery storage it can theoretically deliver the reliable 24/7 baseload power that AI data centres demand.
The catch is that while solar has much lower upfront capex than nuclear, it requires massive overbuild. To reliably power a 100 MW data centre around the clock, you cannot simply install 100 MW of solar panels. You need enough capacity to deliver the full 100 MW to the chips during daylight hours while simultaneously generating roughly 300 MW of extra power to charge the batteries for the 17+ hours of darkness. In practice, supporting a steady 100 MW baseload often demands building a 400 MW solar farm or more.
If you only build enough solar to trickle energy slowly into the batteries, you will never reach a full charge by sunset. A data centre cannot afford to wait for the batteries to catch up — it needs full power the moment the sun dips below the horizon. To keep the batteries topped up, the solar array must be heavily overbuilt so it can deliver a massive surge of current, charging the batteries at high speed while simultaneously carrying the entire live load of the data centre.
In the real world, this problem gets worse when you factor in weather. A string of cloudy days after a sunny one can quickly drain reserves. That is why a solar-plus-battery setup for always-on AI power ends up requiring such enormous overbuild to guarantee a consistent 100 MW baseload.
Gradually, both hyperscalers and investors realised that natural gas could be the best short- to medium-term compromise. It is not carbon-free, but it emits roughly 50% less CO₂ than coal when burned, and it is far more readily available than nuclear or renewables in the near term. This view started gaining real traction by mid-2025.
However, while natural gas itself is abundant — much of it comes as a byproduct of oil production and shale operations — availability alone does not close the demand-supply imbalance. The real bottlenecks sit further down the chain: first with the midstream players, who must build the pipeline infrastructure needed to move gas to where power-hungry data centres actually need it, and then with the generation equipment required to convert that gas into electricity.
Throughout 2026, several projects are underway to unlock more takeaway capacity, particularly in the Permian region. Right now, oil producers in the Permian are often paying others to take the associated natural gas because there is insufficient pipeline capacity to transport it for sale, and flaring is restricted. This distortion has kept local prices suppressed. Once projects like the Blackcomb Pipeline come online in the second half of 2026, that waste byproduct can flow efficiently to Henry Hub and the Gulf Coast, where it can be purchased by power generators serving AI data centre demand. This should stabilise the market and ultimately support firmer prices.
But pipeline capacity is only one link in the natural gas-to-megawatt chain. Even once gas reaches demand hubs, it must be converted to electricity — and gas turbine lead times have stretched to three to four years amid surging orders from power developers. Many existing gas-fired plants along the Gulf Coast and in Texas can absorb new supply without waiting for new turbines, but the broader buildout of generation capacity remains a meaningful constraint in its own right.
This is one of the main reasons we describe the Energy & Power Distribution dam as roughly 1/3 open. New supply is slowly coming through on the transport side, but generation capacity is not yet keeping pace. As both constraints ease, more data centres will be able to secure power, which will add substantial new pressure to the Data Centre segment and further build out the backlogs already forming there.
Another interesting dynamic helping to ease the near-term energy gap is the pivot by Bitcoin miners. These operators have a core competitive advantage in sourcing cheap or stranded energy — often in remote locations far from population centres — and running highly efficient facilities. Many large-scale mining operations had already secured substantial power contracts, land, substations, and cooling infrastructure in these locations, and are now repurposing a meaningful portion of their capacity away from Bitcoin mining and toward AI and high-performance computing workloads.
By leasing or converting their power-hungry facilities to hyperscalers and AI companies, these miners are effectively bringing online ready-to-use megawatts much faster than building new greenfield data centres from scratch. This hybrid approach — where some sites run “mullet mining” (AI in the front, Bitcoin in the back) or fully transition — is providing a flexible, incremental supply of power and compute.
Within our AI Value Chain Framework, these converted Bitcoin miners sit in the Colocation subsegment inside the Data Centre layer, or in the Neo Cloud subsegment within Cloud, AI Models, & Access, depending on how much GPU capacity they actually own. For example, IREN owns the GPUs it operates and therefore functions as more than just a colocation provider, while names like BTDR, CIFR, and CORZ own only about 5-15% of the GPUs they operate and primarily act as power-and-facility hosts.
This miner pivot adds another layer to why the Energy & Power Distribution dam feels slightly open: creative reuse of existing infrastructure is accelerating supply availability in the short term, even as longer-lead traditional sources ramp more slowly.
Looking further out, the energy mix for AI data centres is expected to shift gradually. Renewables paired with battery storage should become substantially more available for firm AI-scale power starting in 2028–2029, helped by falling battery costs and more hybrid projects, though they will still require significant overbuild to deliver true 24/7 baseload. Nuclear contributions will stay limited until 2029–2030, when reactor restarts and the first commercial SMRs begin adding meaningful capacity, with broader impact only accelerating after 2032.
As a result, the approximate share of AI data centre energy demand is projected to evolve roughly as follows (with the balance coming from hydro, thermal, coal, and other sources): In 2026 natural gas is expected to account for around 48%, renewables & storage ~27%, and nuclear ~18%. Natural gas is forecast to peak near 50% in 2027 before gradually declining to ~38% by 2030, while renewables & storage rise toward ~40% and nuclear edges up to ~20%.
The rate at which Bitcoin miners repurpose their compute for AI will provide a useful short-term bridge to AI power demand. If this trend accelerates significantly, it could modestly ease near-term MW pricing pressure and slightly delay incremental demand for new natural gas, renewables, and nuclear capacity. However, the overall effect on the long-term energy mix is likely to remain minor.
This slow but steady surplus of power will first benefit the rest of the Energy & Power Distribution segment — everything involved in getting energy to the data centre, including generation, transmission, substations, and grid infrastructure. However, for the largest GW-scale campuses, hyperscalers are increasingly bypassing the grid altogether. Rather than drawing power from the public grid, they are building their own on-site generation — primarily gas turbines, alongside solar and other renewables — behind the meter. They are doing so both because the grid simply cannot deliver power at that scale fast enough, and because pulling gigawatts from local grids would inflate electricity prices for surrounding communities, creating political and reputational risk. That said, these hyperscalers are legally obligated to eventually connect their behind-the-meter generation assets to the broader grid, which means demand for grid buildout remains strong even when the data centre itself is not relying on grid-delivered power. Companies like Quanta Services (PWR) and Siemens Energy (ADR ticker is SMEGF) are the critical enablers of this infrastructure — manufacturing and installing the substations, transformers, and transmission equipment needed to fulfil those connection requirements. The key question is whether these players can deliver quickly enough to prevent their already large backlog orders from growing even further.
Only after that power reaches the site does the impact hit the Data Centre segment itself — which includes everything inside the facility, from the shell and colocation through to power and cooling systems. Faster shell buildouts and energisation will allow colocation operators to move quicker, but because players like Vertiv and Schneider Electric already carry long lead times (2-4 quarters) and heavy backlogs, the accelerated pace will likely push their order books even higher rather than clearing them. The same dynamic plays out further downstream with optical interconnects (LITE, COHR), which are already struggling to scale fast enough for high-speed GPU cluster connectivity. More available energy before these suppliers can ramp manufacturing will only exacerbate those bottlenecks and pricing power.
In canal terms, it means the upstream Energy & Power Distribution dam continues to open incrementally, relieving some pressure while simultaneously feeding the next closed dam — Data Centres — and building fresh imbalances and rising water levels further along the chain.
Investment Considerations in Energy & Power Distribution
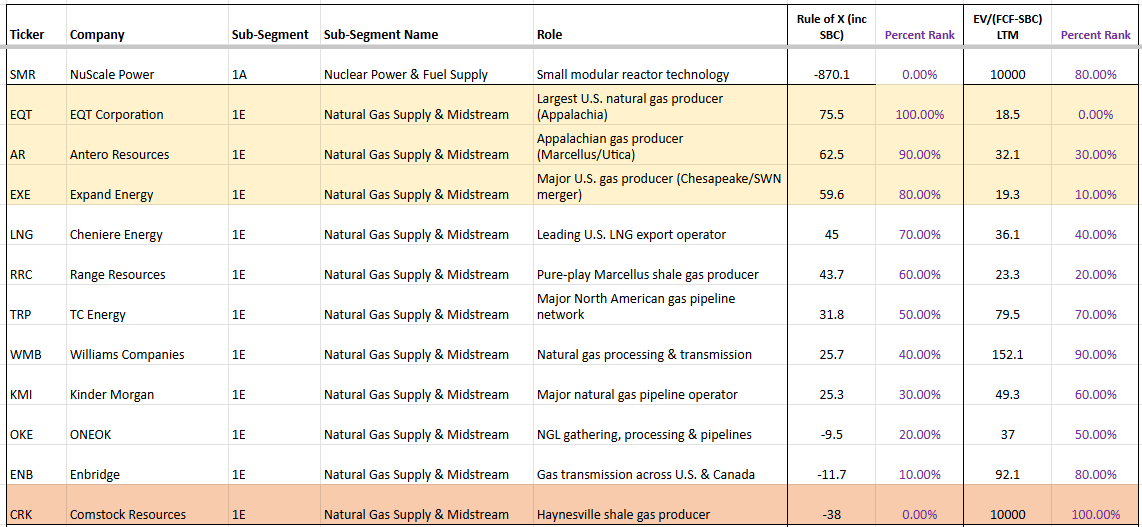
Natural Gas Producers & Transporters
AR, EQT, EXE, & CRK
The top shale gas producers — EQT, AR, and EXE — are viewed by the street as clear near-term winners. They generate solid free cash flow even at moderate Henry Hub prices ($2.50–$3.00/MMBtu) and have secured direct offtake agreements with hyperscalers (Microsoft, Google, Amazon, Meta) for dedicated supply to data centres. This bypasses traditional intermediaries and gives them strong demand visibility through 2028 and beyond. EQT in particular has landed major contracts, including supply for large Pennsylvania AI campuses.
The upcoming Permian pipeline expansions, including the Blackcomb Pipeline (2.5 Bcf/d targeted for H2 2026), will relieve current congestion and associated-gas disposal issues. This should reduce market distortions, support more stable and firmer Henry Hub prices (~$3.80 in 2026, rising toward $4+ in 2027), and allow cleaner flows to high-value Gulf Coast LNG and power demand.
- EQT and AR (primarily Appalachia/Marcellus-focused) benefit as reduced cheap Permian gas flooding northern markets lifts regional realized prices.
- EXE (Haynesville + Appalachia) and especially CRK (pure-play Haynesville) gain from stronger Gulf Coast pricing and low transport costs to nearby LNG and power hubs.
CRK stands out as a high-conviction contrarian alpha play. Its Haynesville acreage sits close to Gulf demand, giving it a structural $0.30–$0.50/Mcfe transport advantage. The March 2026 selection of its Western Haynesville site for a major NextEra/Japan-backed $16B power generation hub (with potential offtake up to 1 Bcf/d) adds a direct “speed-to-power” catalyst for AI. Trading at a low ~4.6x EV/Sales, CRK is also a potential take-private candidate given Jerry Jones’ majority stake and history of consolidation.
Overall, these producers should see continued tailwinds from AI + LNG demand. Apart from CRK, they trade at elevated Rule of X percentiles and are not deeply discounted.
The Blackcomb-driven supply unlock will actually support market stabilization and firmer prices. Once the new pipeline infrastructure comes online, the large volumes of associated natural gas currently being produced as a byproduct of oil drilling in the Permian will finally have an efficient route to market. This will allow keen buyers (LNG exporters and power generators, including AI data centres) to purchase the gas instead of it being flared or sold at distressed prices. Rather than creating a glut, this unlock should reduce market distortions and help lift overall pricing.
Longer term, emerging demand for methane as rocket fuel — most notably from SpaceX's Starship programme — could add yet another significant competing claim on natural gas supply.
Source: Koyfin
Source: Convequity
Alternative Energy - Bypassing the Grid
BE, OKLO, LEU
For an ultra deep dive into nuclear energy (inc. OKLO and LEU), check out our recent three-part report.
Bloom Energy (BE) is the most commercially mature of the three and arguably the most immediately relevant to the AI buildout. The core thesis is deceptively simple: instead of waiting years for a utility to upgrade transformers, build substations, and run new transmission lines, Bloom connects to the existing underground natural gas pipeline — infrastructure that already has massive capacity headroom in most industrial areas — and generates electricity on-site using solid oxide fuel cells (SOFC). The analogy is straightforward: the gas pipeline network is the highway already running under every industrial area — all the data centre operator needs to do is build a short driveway connecting their site to it. This collapses deployment timelines from years to months — Bloom can deliver 50–100MW of on-site power in 90–120 days, which in the current environment where utility interconnection queues stretch three to five years makes speed-to-power arguably the most valuable commodity in the entire data centre supply chain.
The technical advantages compound beyond just speed. Bloom's fuel cells do not burn natural gas — they internally reform it into hydrogen using heat and steam, then convert it electrochemically into electricity at roughly 60% electrical efficiency, meaningfully cleaner than a conventional gas turbine. Critically, fuel cells naturally produce DC power. AI chips run on DC, but the grid delivers AC, meaning traditional data centres lose significant energy through AC-to-DC conversion at every stage. Bloom's architecture can feed DC power directly into a high-voltage DC bus serving GPU racks, eliminating conversion losses, reducing cooling load, and in many configurations removing the need for massive UPS battery rooms entirely. The energy density is also striking — Bloom can pack 100MW into roughly one acre, whereas an equivalent firm solar-plus-battery installation would require hundreds of acres and enormous capital tied up in panels that sit idle during weather gaps.
The commercial traction is no longer speculative. The $5 billion Brookfield deal, announced in late 2025, was structured as project finance — Brookfield provides the capital to build on-site AI power infrastructure while Bloom supplies the technology and earns both high-margin hardware revenue and 20-plus years of recurring service fees. The partnership solved Bloom's historical weakness of capital intensity without dilutive equity raises, contributed to a record $20 billion backlog, and helped the company achieve its first GAAP operating profit in early 2026 — shifting the narrative from speculative green tech to critical AI infrastructure. The remaining question is execution: whether Bloom can convert that backlog into sustained GAAP net income at scale, and whether the economics hold once financing partners take their share. On emissions, Bloom remains primarily a natural gas story today — cleaner than the grid, but not zero carbon — though its fuel-flexible platform can transition to green hydrogen as that feedstock matures, likely post-2030.
Oklo (OKLO) represents the higher-conviction, longer-duration bet. Backed by Sam Altman and with early investment from Chris Wright — now US Secretary of Energy — Oklo is developing compact fast reactors designed to function as deployable nuclear batteries.
To understand why Oklo's design matters, it helps to understand what it eliminates. In a conventional sodium-cooled fast reactor, the core generates intense heat through nuclear fission. That heat needs to get out of the core and into a power conversion system (typically a turbine) to produce electricity. The traditional solution is an external coolant loop: liquid sodium is pumped through pipes into the reactor core, absorbs the heat, and is then pumped back out through more pipes to a separate heat exchanger located outside the reactor vessel, where the thermal energy is transferred to a secondary fluid that drives the turbine. This works, but it creates a significant engineering and safety burden. Sodium is violently reactive — it ignites on contact with air and reacts explosively with water. Every pipe joint, weld, valve, and pump in that external loop is a potential leak point, and a sodium leak is not a minor maintenance issue — it is a serious safety event. The external plumbing also adds physical bulk, mechanical complexity, and cost, all of which make conventional SFRs difficult to standardise and slow to build.
Oklo's Aurora design eliminates this external loop entirely. Instead of circulating sodium through pipes outside the vessel, Aurora uses an array of sealed heat pipes embedded directly within the reactor core itself. Each heat pipe is a simple, self-contained metal tube containing a small amount of working fluid. As the nuclear fuel generates heat, the fluid inside the heat pipe absorbs it, vaporises, travels passively up the pipe to a cooler section where it transfers its energy to the power conversion system, condenses, and flows back down by gravity — no pumps, no external piping, no moving parts. The principle is identical to the copper heat pipes used in laptop cooling, just engineered for nuclear temperatures. Critically, the sodium and fuel remain sealed together inside a compact vessel with nothing circulating outside it. Because sodium never leaves the vessel, it cannot leak, which removes the single largest safety concern associated with conventional SFR designs. The result is a dramatically simpler, more compact reactor with fewer failure modes, stronger inherent safety, and a form factor far better suited to factory production and modular deployment.
The intended deployment model is modular: each unit produces up to 75 MWe, fuel is loaded at installation, the reactor operates for approximately 20 years without refuelling, and when spent, the entire core module is swapped out for a fresh one. Data centre operators can add reactors incrementally as demand grows rather than committing to a single massive power plant. The regulatory path remains the key risk — Oklo's first combined licence application to the NRC was denied in 2022 for insufficient technical detail, though a revised application was accepted for review in 2024. This is realistically a 2028+ revenue story, making it a call option on the thesis that AI's power appetite will eventually exceed what gas and renewables can deliver on-site, and that nuclear is the only carbon-free baseload source dense enough to fill the gap.
Centrus Energy (LEU) is the upstream chokepoint that makes the entire next-generation nuclear thesis — Oklo and every other advanced reactor design — physically possible. Most advanced SMR designs require HALEU (High-Assay Low-Enriched Uranium), enriched to between 5% and 20% U-235, without which they simply cannot operate. Centrus operates the only NRC-licensed uranium enrichment facility in the United States and in November 2023 achieved the first production of HALEU on American soil in approximately 70 years at its Piketon, Ohio plant. The problem is scale: its current demonstration cascade produces roughly 900 kilograms per year, while the industry will need an estimated 40 metric tonnes by 2025–2027 just to fuel initial demonstration reactors, with demand potentially exceeding 150 metric tonnes annually by 2030 as commercial fleets expand. Current capacity covers less than 2.5% of even the near-term requirement.
The supply gap is compounded by geopolitics. The only commercial HALEU supplier globally was Russia's TENEX, and following US sanctions on Russian nuclear fuel imports in 2024, domestic production has become a national priority — backed by roughly $2.7 billion in dedicated appropriations. Centrus's centrifuge design is technically scalable but faces a chicken-and-egg problem: it needs guaranteed offtake to justify expansion, while reactor developers hesitate to commit without guaranteed fuel. As that deadlock breaks and SMR deployments scale, demand flows almost unavoidably through Centrus's facility.
These three companies offer a spectrum of risk and time horizon. Bloom is the near-term, deployable-today solution already generating revenue and converting hyperscaler contracts. Oklo is the medium-term bet on SMR commercialisation. Centrus is the pick-and-shovel play underpinning the entire next-generation nuclear fuel chain. Together, they represent the market's growing recognition that the AI power problem will not be solved by the grid alone.
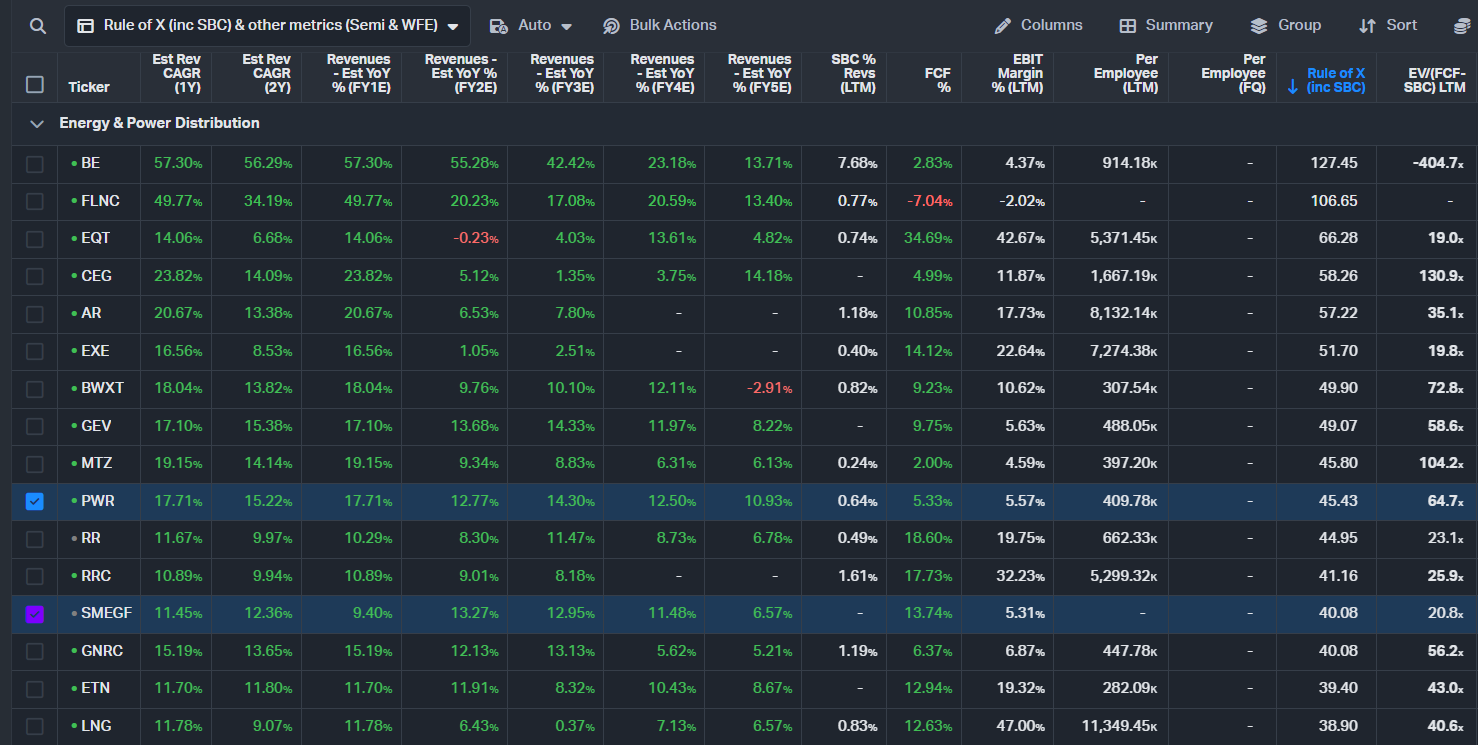
Power Distribution
PWR & SMEGF
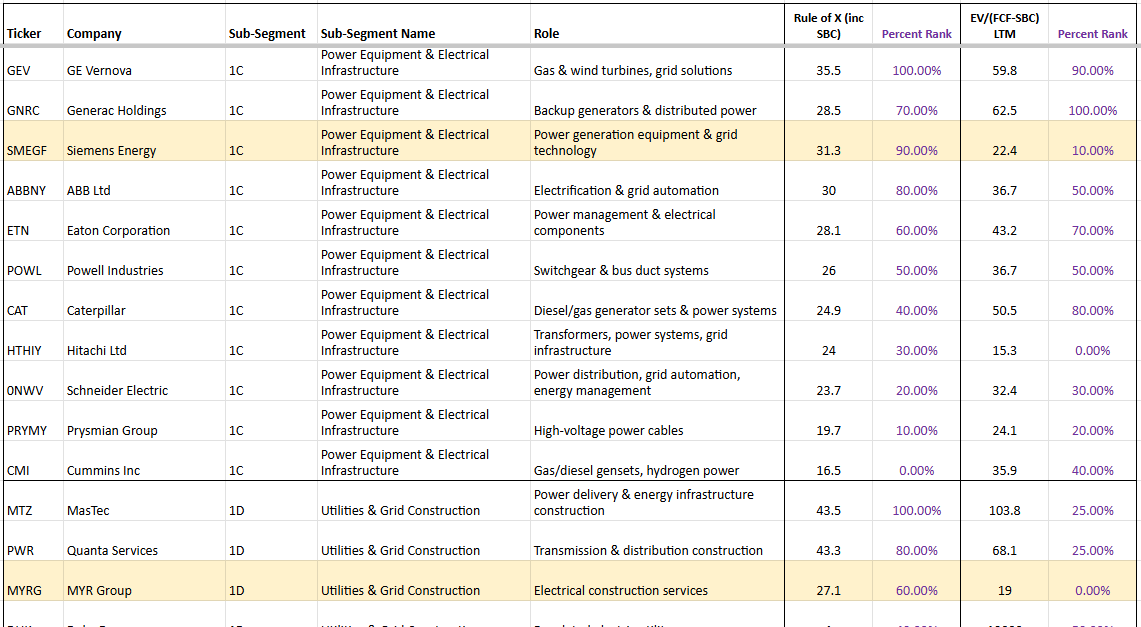
Two names stand out in the Power Equipment & Electrical Infrastructure and Utilities & Grid Construction subsegments: Siemens Energy (SMEGF) and Quanta Services (PWR).
Siemens Energy operates from the grid to the fence — high-voltage transformers, switchgear, substations, HVDC transmission, and grid connections. Every new megawatt of AI compute has to pass through their equipment before it ever reaches a data centre. The emerging 800V DC “grid-to-chip” architecture actually plays to Siemens’ advantage: it improves overall power-delivery efficiency (from ~90% to 96%+), which lowers the effective cost per megawatt of useful compute. That efficiency makes it viable to build even larger hyperscale facilities, driving higher total MW demand through the grid — classic Jevons paradox that expands Siemens’ TAM. Schneider Electric, by contrast, sits inside the data centre on the power-distribution and cooling side. While the 800V shift requires redesigning parts of its product portfolio, the increased complexity and technical demands likely reinforce Schneider's advantage over lower-cost competitors — though its path is more execution-dependent than Siemens', whose grid-to-fence positioning benefits regardless of how the architecture evolves inside the facility.
PWR is the already-noticed beta play in the segment. The company specialises in transmission & distribution construction — building the actual lines, substations, and grid infrastructure that connect new generation to data centres. With its record ~$44 billion backlog (as of early 2026), PWR has multi-year visibility and is widely seen as the leader in what it does. The market has already priced in much of that strength, so the stock is trading closer to perfection and offers solid but less explosive upside.
Siemens Energy, on the other hand, shows an attractive Rule of X (31.3) paired with a noticeably lower EV/(FCF–SBC) multiple (22.4x). Its massive multi-year grid backlog provides excellent cycle durability, and the troubled Gamesa wind business is essentially a free option — if it reaches breakeven, margins and the stock could re-rate sharply. However, Siemens continues to add backlog faster than it can convert it, constrained by production capacity it cannot ramp quickly enough. That makes it a high-quality compounder but potentially limits near-term alpha. PWR may be the more interesting opportunity precisely because it is actively building US-based transformer manufacturing capacity — a rare player positioned to actually address the bottleneck rather than just benefit from it. We haven't had time yet to dive deeply into MYR Group, another highlighted name in the Utilities & Grid Construction subsegment, but it also warrants a closer look for similar reasons.
Both stocks give exposure to the half-open Energy & Power Distribution dam continuing to open and feed the next closed dam downstream. Siemens offers backlog-driven durability at a reasonable multiple; PWR offers the higher-conviction play on bottleneck resolution and remains the purest beta in the grid buildout.
Data Centre
The next dam in the canal is firmly closed: Data Centres. This segment — everything from the shell and colocation through to the power, cooling, networking, and servers inside the facility — is currently the most visible bottleneck in the entire AI value chain.
AI workloads simply cannot run effectively in most existing data centres. Training and inference at scale require extreme power densities of 50–100+ kW per rack, compared with the 5–15 kW that traditional facilities were designed for. They also demand liquid cooling (direct-to-chip or immersion) because air cooling cannot handle the heat generated by thousands of high-power GPUs working in parallel. Retrofitting legacy buildings for these requirements is extremely difficult or outright impractical — the structural loads, power delivery systems, plumbing for liquid cooling, and low-latency networking architecture are fundamentally different. As a result, hyperscalers and colocation providers are forced to build largely new, purpose-built facilities from the ground up.
That is why colocation demand is exploding. New shells must be constructed and energised before anything else can happen inside them.
Once the shell is in place, the real pressure hits the other subsegments. Power & Cooling providers — Vertiv, Schneider Electric, Vicor, and Modine — are already sitting on multi-year backlogs. Their equipment (PDUs, UPS systems, liquid cooling loops, chillers) carries lead times of up to four quarters — shorter than the multi-year waits facing the grid and energy segment, but still materially longer than AI servers, which can be assembled in factories and are more plug-and-play by comparison. Much of the installation and integration must also happen on-site, adding further friction. NVIDIA's increasingly scale-out architectures — moving from Hopper to Blackwell, then to Rubin and eventually Feynman — are only amplifying the challenge. Each new generation requires even higher power delivery precision, more sophisticated cooling, and tighter integration, further stretching these backlogs for the specialists who supply them.
The same dynamic is playing out in Networking/Optical. The sheer throughput needed for thousands of GPUs to communicate in a single cluster has rendered traditional copper cables unusable beyond a few metres. Rack-to-rack communications now rely heavily on optical interconnects supplied by companies like LITE and COHR. The bottleneck here is already severe, and it will intensify further when the industry moves to 3.2T optical modules. At those speeds copper will only be viable for roughly two metres before jitter becomes unacceptable, meaning optical will be required even for intra-rack GPU connections. Compounding the issue is a massive global shortage of indium phosphide, the critical material used to produce the lasers inside these optical modules.
Servers (SMCI, DELL, HPE) are not the current bottleneck. These companies can scale assembly in factories rather than on-site, so they have been able to keep up so far. However, any energy unlock — some of which will occur in the second half of 2026 once Permian gas takeaway capacity comes online — will dramatically increase demand for NVIDIA GPUs. That extra GPU demand will put fresh pressure on TSM's capacity and, downstream, on server integration and delivery. The server makers themselves are not creating the bottleneck; they are simply the next link in the chain that will feel it. It is also worth noting that even if energy and GPU supply constraints ease simultaneously, the optical interconnect bottleneck discussed earlier could act as an independent cap on how quickly clusters can actually scale — thousands of GPUs are useless if they cannot communicate at the required throughput, meaning the networking layer may ultimately gate the pace of the buildout more than the servers themselves.
In canal terms, the Data Centre dam is still firmly closed, and water levels (backlogs, pricing power, and inventory pressure) are rising fast. More energy will not relieve this pressure — it will accelerate new shell buildouts and colocation connections, which will pour even more demand into the power & cooling, networking, and eventually server subsegments. The centre of gravity of the bottleneck is shifting, and the imbalances inside Data Centres are only going to intensify in the near term.
Investment Considerations in Data Centre
Colocation
BTDR, CIFR, CORZ
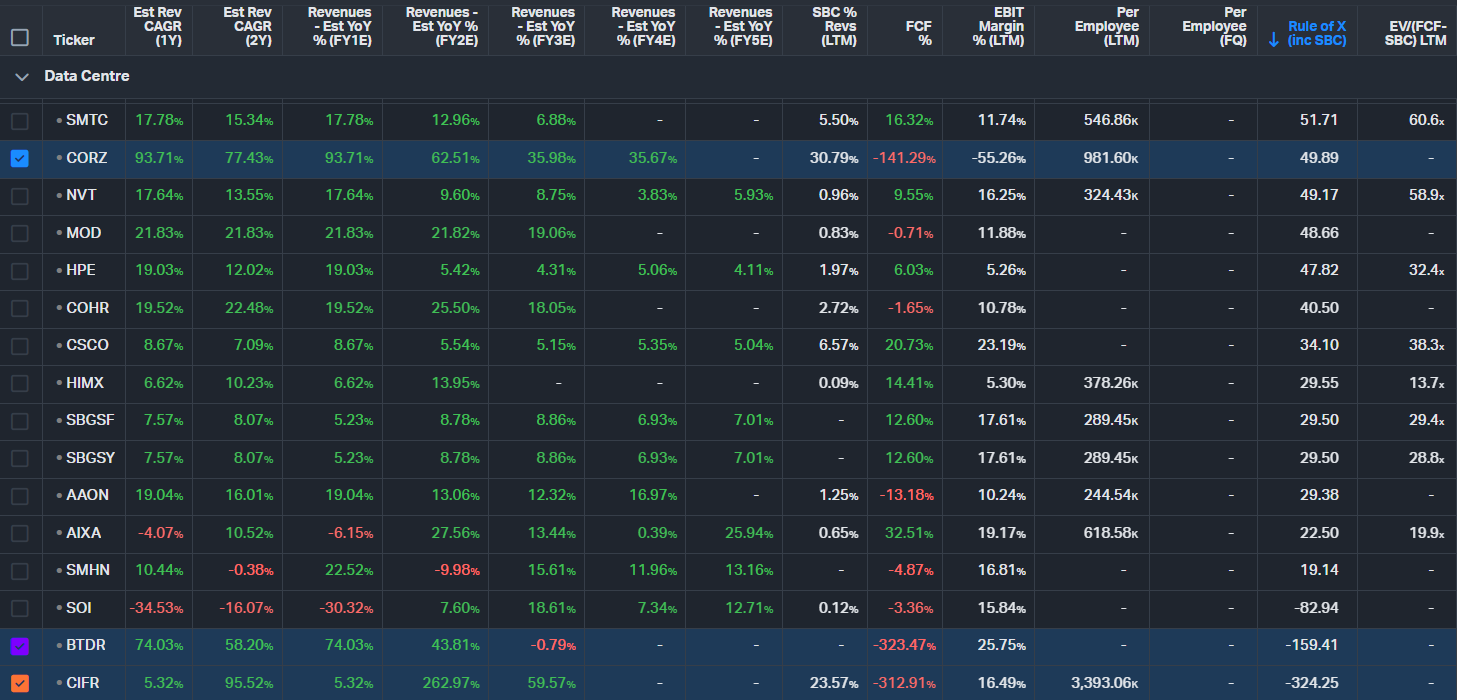
The converted Bitcoin miners — BTDR (Bitdeer), CIFR (Cipher Digital), and CORZ (Core Scientific) — are among the most compelling names in the Colocation subsegment right now.
Bitcoin mining operations are uniquely well-positioned to pivot to AI. They already own high-density power infrastructure, substations, cooling systems, and large plots of land purpose-built for massive, always-on compute loads. Their facilities were designed from the ground up to run 24/7 at extreme power densities — exactly what AI workloads require. While ASICs were originally built for Bitcoin mining, many of these sites can be rapidly reconfigured for AI inference (and in some cases, lighter training workloads) by swapping in GPU clusters. This gives them a structural speed advantage: they can bring online usable AI capacity in months rather than the 2–4 years it typically takes to develop a traditional greenfield data centre.
In our AI Value Chain Framework, these converted operations sit primarily in the Colocation subsegment (or Neo Cloud in some cases). They are adding meaningful value by delivering ready-to-use power and space to hyperscalers much faster than conventional players.
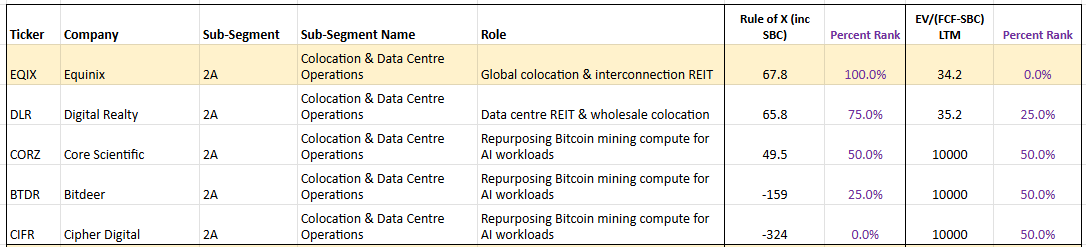
By comparison, traditional colocation leaders like EQIX have excellent long-term fundamentals and a very high Rule of X, but they face challenges beyond just the slow, capital-intensive process of building or acquiring new facilities. EQIX operates a retail colocation — or 'data centre hotel' — model, designed to serve many tenants at relatively modest power densities per rack. That model is being structurally challenged by the AI-driven shift in rack density: a single AI rack can now draw over 100kW, which historically would have classified as a wholesale deployment in its own right. EQIX's infrastructure and competitive moat were not built for this paradigm, and adapting to it requires more than just adding new capacity — it demands a rethinking of power distribution, cooling, and facility design. This is precisely why Bitcoin miners have found the AI transition so much easier: their facilities were already built around maximizing power draw per square foot, with heavy-duty electrical infrastructure, substations, and cooling designed for dense, power-hungry workloads — an architecture that maps naturally onto AI/GPU compute without the same structural overhaul EQIX faces. On top of this, EQIX must still navigate the full Data Centre dam — permitting, construction, and on-site integration — which is currently the main bottleneck.
The upcoming energy unlock (Permian gas takeaway capacity) will have only limited impact on these miners. They already secured their power contracts years ago, so their main remaining bottleneck is GPU supply (NVIDIA/TSM availability), not raw megawatts. That said, a broader increase in energy supply could modestly help by lowering their overall power costs if they have any variable-rate or expandable contracts.
This structural difference gives the Bitcoin miners a clear edge in speed-to-power and operating leverage over traditional names like EQIX. As energy supply gradually unlocks elsewhere, these miner-turned-AI providers should be among the quickest to scale capacity and capture revenue in the near term.
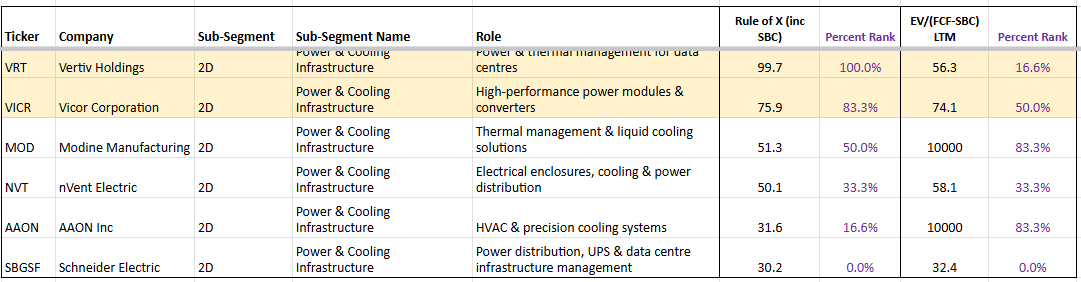
Power & Cooling
Schneider Electric, VRT, MOD
Power & Cooling is currently one of the bottlenecks inside the Data Centre dam, although less severe tha Networking & Opticals. These companies supply the physical infrastructure that turns raw megawatts into usable, cooled racks — and their lead times are 2-4 quarters.
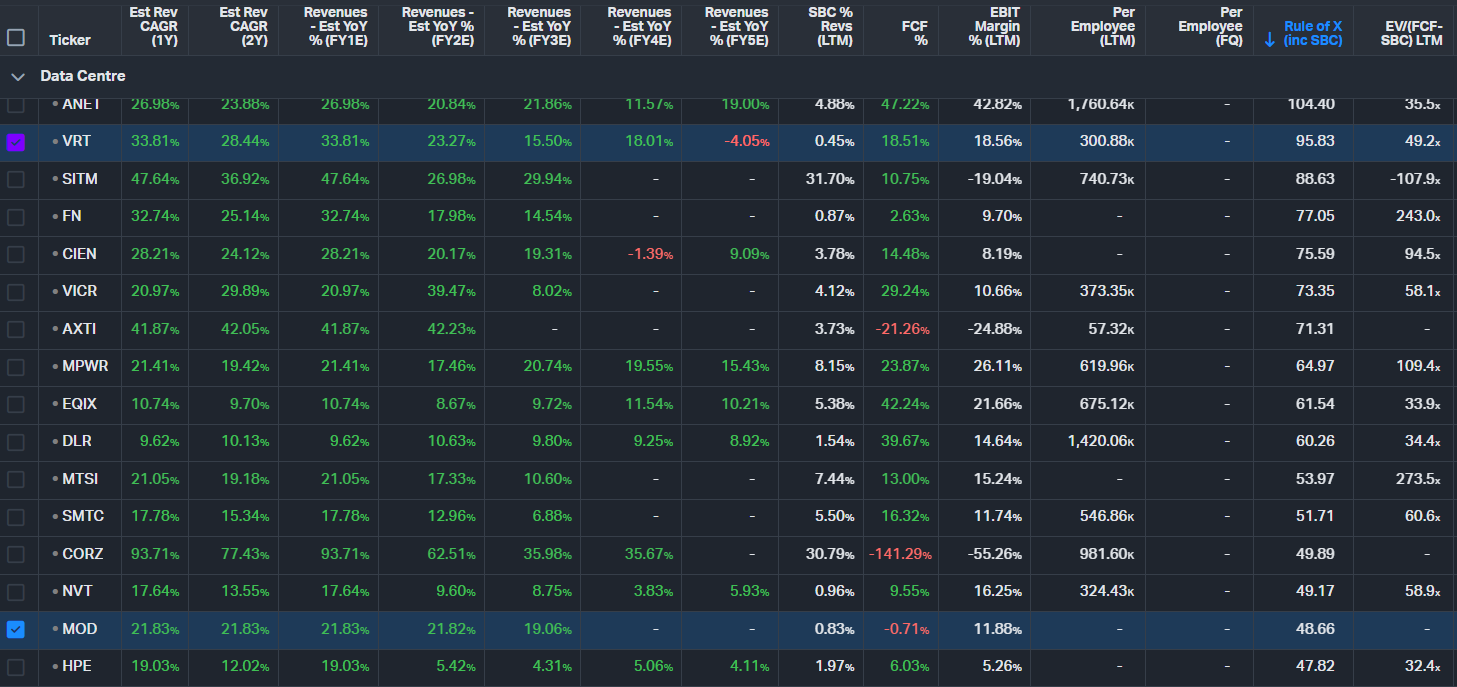
Vertiv (VRT) is the integrated full-shell provider: power delivery, liquid cooling loops, thermal management, and racks. It is riding the highest organic growth in the group (~28% in 2026) with a Rule of X of 95.83 (100th percentile in the subsegment) and an EV/(FCF–SBC) multiple of 49.2x. Its moat is twofold. First, the on-site engineering complexity — you cannot "plug in" a 1.25 MW liquid-cooling manifold the way you can rack a server. Second, and perhaps more importantly, Vertiv operates as a prime contractor for the power and cooling supply chain: it integrates and qualifies a deep bench of tier-2 component suppliers (many based in China), packages them under its own brand, and delivers a turnkey solution at a premium. NVIDIA in particular leans heavily on this model, preferring to work with Vertiv as a single integration partner rather than directly qualifying white-label or downstream manufacturers — likely because the thermal and power delivery stack is too complex and too far from NVIDIA's core competency to manage in-house. This hands-on integration role is exactly why Vertiv's backlog keeps growing even as power becomes more available. That said, not all hyperscalers are content to pay the prime-contractor premium. Google, for instance, is actively working to directly source and qualify Chinese manufacturers, bypassing the Vertiv and Schneider layer entirely in pursuit of aggressive cost optimisation. If this approach gains traction among other hyperscalers, it could pressure Vertiv's margins over time — though the sheer complexity of integration and the speed at which capacity needs to be deployed may limit how quickly customers can realistically disintermediate.
Schneider Electric (ADR ticker is SBGSF) is the traditional "grid-to-chip" leader, strong in PDUs, UPS systems, busways, and building management software (EcoStruxure). It dominates legacy AC architectures. The shift to 800V DC is not a major headwind for Schneider — it actually increases component sophistication and power-density potential, which should drive net demand uplift over time. Schneider remains the steady, blue-chip compounder in the group, though its growth is more moderate given its large base.
Modine (MOD) is the pure-play thermal specialist and the highest-beta name in the subsegment. Focused exclusively on heat rejection (TurboChill hybrid chillers, stainless-steel DLC systems, and immersion-ready solutions via TMGcore), Modine is targeting 50–70% growth in 2026. It has secured long-term supply agreements with hyperscalers, dedicated production lines, and roughly five years of backlog visibility. The upcoming Reverse Morris Trust spinoff of its legacy automotive business in Q4 2026 will make it a clean data-centre play, potentially unlocking a significant multiple re-rating.
From the Rule of X dashboard, VRT leads with the strongest forward growth profile, followed by MOD (48.66) and Schneider (30.2). All three are benefiting from the same secular tailwind, but they offer very different risk/reward profiles: Vertiv for scale and integration, Modine for pure-play speed and re-rating potential, and Schneider for stability and global reach.
The upcoming energy unlock will not relieve pressure on this subsegment — it will accelerate it. More available MWs simply mean more shells get energised faster, driving even higher demand for the specialised power and cooling equipment these three companies provide.
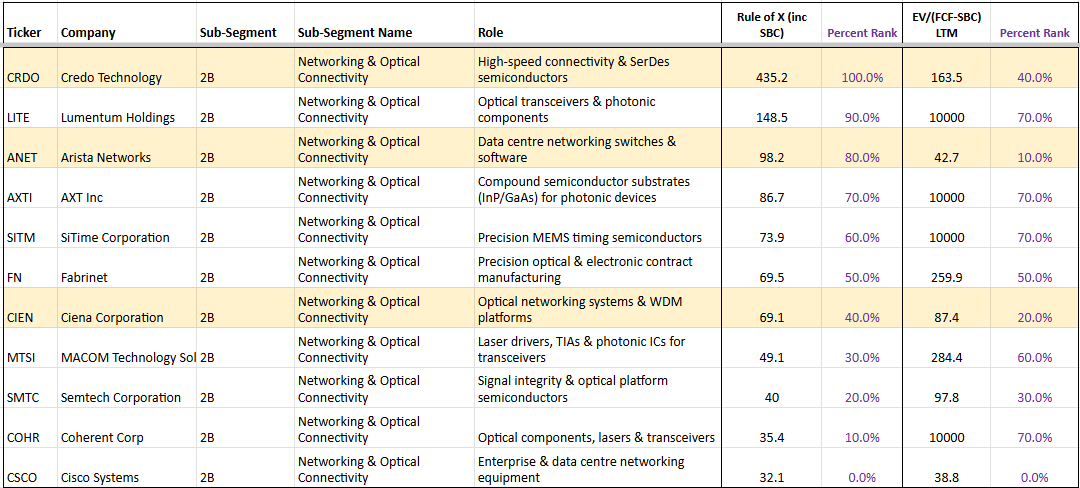
Networking/Optical
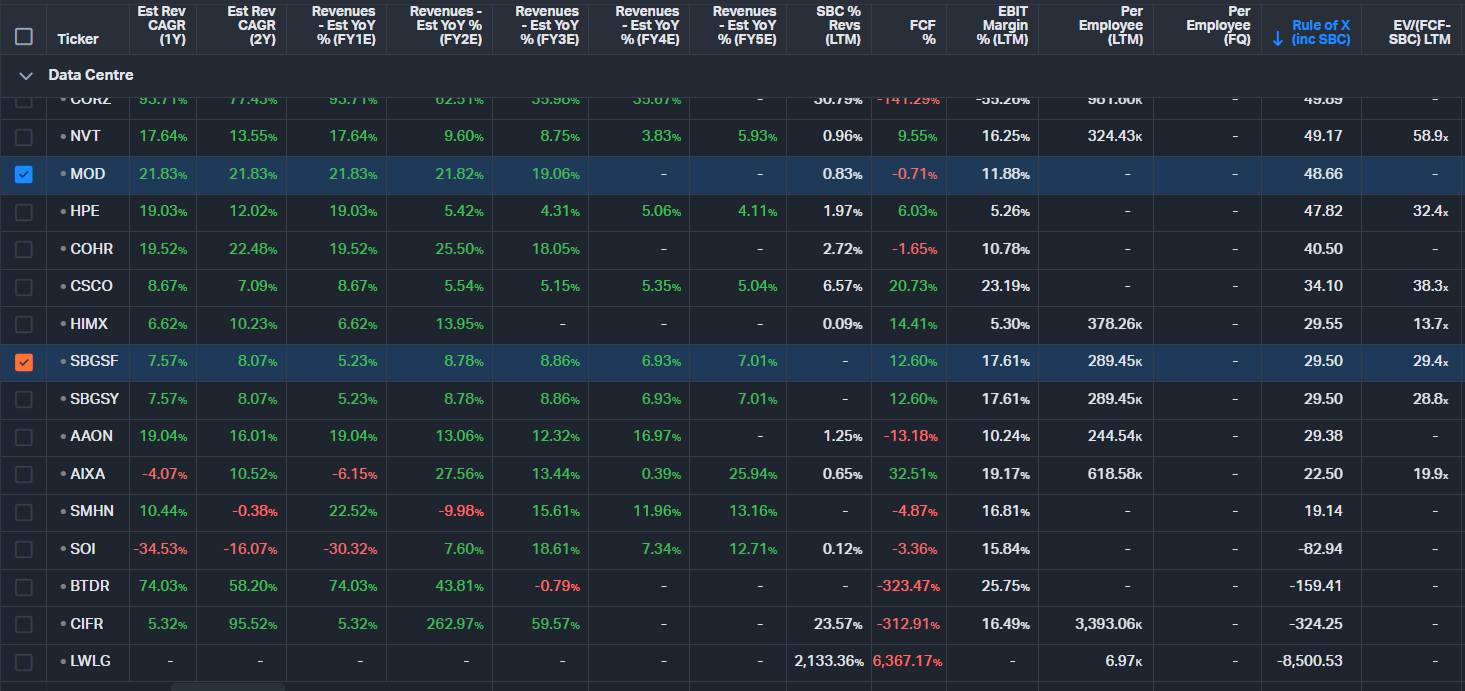
The Networking/Optical layer is one of the most acute bottlenecks in the entire AI value chain. As GPU clusters scale out dramatically, traditional copper interconnects are hitting physical limits, driving explosive demand for high-speed optical solutions. Much of the market's attention — and retail enthusiasm — has gravitated toward Lumentum (LITE), which has become something of a poster child for the AI optical trade - a company we deep dived into for the first time back in 6th Nov-25. LITE's outlook remains positive, but investors who stop there are barely scratching the surface. The optical supply chain runs far deeper than transceiver module assemblers, spanning substrates, analog signal conditioning, photonic integration, precision manufacturing equipment, test infrastructure, and inter-DC coherent optics.
Many of the companies operating in these layers have not yet gone parabolic and offer meaningful alpha potential for investors willing to look further upstream and downstream. Most names in this space are trading at elevated multiples because both customers and investors clearly recognise how critical they are to enabling the optical fabric required for massive AI training and inference clusters.
Only SMCI and HIMX are currently trading at multiples that are not excessively stretched. We will be posting deeper dives into these names in the coming weeks. However, despite some of the following stocks with very high multiples, given their criticality to the optical industry, we consider there is still some alpha to capture.
POET Technologies (POET)
POET Technologies is an emerging pure-play photonic integrated circuit company developing highly integrated optical engines and transceiver modules using its proprietary Optical Interposer platform. It enables co-packaged optics (CPO) and low-power, high-bandwidth chip-to-chip and rack-to-rack interconnects for large-scale AI GPU clusters. By integrating lasers, modulators, and detectors onto a single silicon-based platform, POET aims to deliver significantly lower power consumption and better manufacturability at scale compared to traditional discrete optical solutions — directly addressing the exploding bandwidth and efficiency demands of next-generation AI training and inference networks.
Ciena Corporation (CIEN)
Ciena is a leader in high-capacity, low-latency optical networking solutions, and its core competitive edge lies in DCI — data centre interconnect — which is becoming increasingly critical as the industry enters the era of scale-across. The progression has been logical: the AI infrastructure buildout began with scale-up (making individual chips and systems more powerful), moved to scale-out (connecting thousands of GPUs within a single data centre cluster via NVLink and InfiniBand), and is now pushing into scale-across, where training runs and inference workloads are federated across multiple geographically distributed data centres. This shift is being driven by necessity — single-site clusters are hitting hard ceilings on available power, grid access, and permitting, meaning hyperscalers increasingly cannot concentrate enough compute in one facility to keep pace with model scaling. The only way to keep expanding effective cluster size is to link sites together with enough bandwidth and sufficiently low latency to make distributed training viable over distances of tens to hundreds of kilometres. That is squarely Ciena's home turf. Its coherent optics platforms, pluggable engines (including the new high-density, low-power Vesta 200 6.4T CPX), and hyper-rail photonics are purpose-built for inter-DC distances of tens to hundreds of kilometres, well beyond the range of intra-DC interconnect technologies like NVLink and InfiniBand. As scale-across demand accelerates, Ciena is positioned as the critical fabric connecting the increasingly distributed AI compute footprint.
AXT Inc (AXTI)
AXT is the dominant — and effectively monopoly — producer of indium phosphide (InP) substrates, the essential material for high-speed lasers used in optical transceivers and interconnects. As AI drives demand for faster rack-to-rack and intra-rack optical links (moving toward 3.2T modules), AXT's InP wafers are a foundational bottleneck enabler — powering the lasers that make high-bandwidth, low-power optical connectivity possible at scale. The investment logic is straightforward: when optical transceiver demand skyrockets, InP wafer demand moves in lockstep, and nearly all of that demand flows through AXT.
Soitec (SLOIF)
Soitec provides specialised engineered substrates, particularly Photonics-SOI and Lithium Niobate on Insulator (LNOI), that power silicon photonics and co-packaged optics (CPO). These substrates are not optional — InP and virtually every other substrate used in optical components requires SOI to achieve clean signal strength and low noise, making Soitec's technology a near-universal dependency across the optical supply chain. Like AXT in InP wafers, Soitec holds a near-monopoly position in this niche, meaning the coming demand boom in optical interconnects flows almost unavoidably through its fabs. Its substrates enable higher data rates, lower power consumption, and better signal integrity, supporting the transition to denser, more efficient chip-to-chip and rack-level optical connectivity required for next-generation AI clusters.
Semtech (SMTC)
Semtech delivers high-performance analog ICs across two critical points in the AI data centre signal chain. Inside optical transceiver modules, it supplies laser drivers and transimpedance amplifiers (TIAs) that support 224G, 448G, and multi-vendor 1.6T interconnects with low power and ultra-low latency, making it a key enabler for linear pluggable optics (LPO) and retimed optics. On the host PCB side, Semtech's core growth driver is its CTLE (Continuous-Time Linear Equalizer) chips — small but critical analog components that clean up high-speed electrical signals as they travel across SerDes interfaces before reaching the optical module. As data rates push to 224G and beyond, signal degradation worsens, and more CTLE correction is needed. This creates an interesting competitive dynamic: Broadcom's 224G SerDes is considered best-in-class and needs less signal correction, while MediaTek's competing 224G SerDes requires more CTLE chips per link to match Broadcom's signal quality. As MediaTek gains share as a lower-cost alternative in AI networking, Semtech benefits directly from the performance gap — more CTLE chips per board means more revenue per link.
Himax Technologies (HIMX)
Himax brings wafer-level optics expertise, including advanced nanoimprint lithography for micro-optics and lenses used in optical components. It is emerging as a supplier of critical light-bending elements for next-generation optical interconnects, helping enable higher-density, cost-effective optical solutions inside AI data centres.
SUSS MicroTec SE (SESMF)
SUSS MicroTec provides precision equipment and process solutions for micro-optics manufacturing, including lithography, bonding, and imprint technologies. It supports high-volume production of micro-lens arrays and photonic components essential for advanced optical interconnects and co-packaged optics in AI-scale GPU clusters.
Keysight Technologies Inc (KEYS)
Keysight is the critical test and validation partner for high-speed optical networking. It supplies 224G and emerging 448G test solutions (oscilloscopes, BERTs, and performance testers) that allow vendors to validate optical transceivers, interconnects, and 1.6T+ links under real AI data centre conditions, ensuring reliability and performance at extreme scale.
These companies form the enabling layer for the optical fabric that keeps massive GPU clusters communicating at the speeds AI demands. The bottleneck here remains intense and is expected to worsen with the move to higher-speed modules.
Servers
SMCI, DELL, HPE
Super Micro Computer (SMCI) stands out as our preferred name in the Servers subsegment. Unlike traditional OEMs, SMCI is deeply involved in the actual design and customization of high-density AI servers. It works closely with NVIDIA and hyperscalers to co-engineer rack-scale solutions optimized for liquid cooling, high-power GPUs, and next-generation architectures. This adaptability allows SMCI to move faster from chip availability to full deployment, giving it a clear edge in speed-to-market.
Dell (DELL) and HPE are primarily OEMs that rely on strong global sales, marketing, and service networks rather than deep in-house design capabilities for AI-optimized servers. They integrate third-party components effectively but lack the same level of early-stage co-design agility that SMCI brings to the table.
A key caveat with SMCI is the recent controversy: in March 2026, U.S. authorities charged a co-founder/board member along with other individuals linked to the company in a scheme to divert approximately $2.5 billion worth of AI servers containing NVIDIA GPUs to China in violation of export controls. SMCI itself has not been charged, and the company has stated it is cooperating with the investigation. Shareholder lawsuits alleging securities fraud have also been filed. While these issues have created headline risk, they have not altered the fundamental demand tailwind for SMCI’s AI server solutions.
Overall, SMCI’s design-led approach makes it the most leveraged pure-play server beneficiary of the ongoing GPU buildout, even as the broader energy unlock accelerates demand across the subsegment.