
Snowflake - The Apple Of MDS -Part 1
Summary
- SNOW is positioned very well at the centre of OLAP (Online Analytical Processing), the Modern Data Stack (MDS), and the growthy areas of the data sector.
- There is substantial amount of competition across all disaggregated stacks, catalysed by the Cambrian-like explosion of MDS.
- The market should be big enough for both integrated players (like SNOW) and disaggregated players (like Databricks) to continue to thrive.

RomoloTavani/iStock via Getty Images
Since its 2020 IPO, Snowflake has been one of the hottest tech stocks, both for its growth and hyped valuation, but also for the disruptive innovation it brought to the industry. SNOW is not only rapidly growing its core Cloud Data Warehouse (CDW) market, but also expanding into adjacent horizontals (data marketplace) and verticals (cybersecurity).
Our friend Francis Odum has recently published a report titled "Snowflake vs. Databricks: The Clash of Titans". Our analysis is built upon this and several other analysts' insights. As an equity research house, however, we will focus more on the competitive dynamics, and will make some predictions for the future.
We are going to divide the Snowflake full report into three parts.
- Part 1 focuses both on mapping a general landscape of the industry and on discussing areas of MDS (Modern Data Stack) largely uncovered by public investors.
- Part 2 will be a comprehensive analysis of the competition accompanied with judgements on where SNOW and the industry are heading.
- Part 3 focuses on SNOW's financial and valuation analysis.
The following are the public companies, startups, and associated open source projects discussed to varying degrees of detail (related open source projects are in brackets):
SNOW, AMZN, GOOGL, Databricks (Spark & Delta Lake) , Starburst (Trino), Ahana (Presto), Dremio (Dremio Sonar), Coiled (Dask), Onehouse (HUDI), Tabular (Iceberg), Fivetran, Dbt (Dbt), Astronomer (Airflow), CRM, PANW, S, PLTR, SPLK, Cohesity, ORCL, MSFT, TDC.
Public investors' view over SNOW competitors
Investors are constantly looking for an information edge to gain alpha. We've been able to generate useful insights leading to alpha for PANW and FTNT by looking deeper at the competition across the startup and incumbent landscapes. We believe SNOW is another example where public investors don't comprehensively study the competition, and instead settle for analysing just public peers.
Based on our research, we think it's clear that public investors see AMZN's AWS Redshift, GOOGL's GCP BigQuery, and to a lesser extent Databricks, as SNOW's major competitors. And a quick calculation would derive the conclusion that SNOW's competition is dimissable:
- Redshift, albeit being the first to usher in the era of CDW, failed to deliver disruptive innovation via the separation of storage and compute via cloud computing elasiticity. Now, AWS focuses more on co-selling SNOW as it helps it land easy wins for greater spending on S3 and other services.
- BigQuery had a huge headstart as Google is the master of data infrastructure technologies. However, due to its consumer gene, and tilt towards a closed ecosystem, thus far BigQuery hasn't, and probably never will, achieve meteoric commercial success in the foresseable future.
- Databricks collaborates with SNOW on 80% of deals, hence it is not a direct competitor.
- MSFT, TDC, ORCL and others have much weaker products and won't be effective competitors to SNOW in the future.
Interestingly, and what is a core aspect of our SNOW analysis and thesis, is we believe these tech giants are backing several startups and open source projects that do indeed pose a competitive threat to SNOW. It's just that they aren't strong and/or direct competitors themselves. There are also vertically specialised vendors who could potentially compete with SNOW, such as PANW, S, PLTR, and Cohesity - we'll cover these as we proceed through the report.
What Snowflake is?
Before we talk about the landscape, let's have a quick review of what SNOW is.
Product
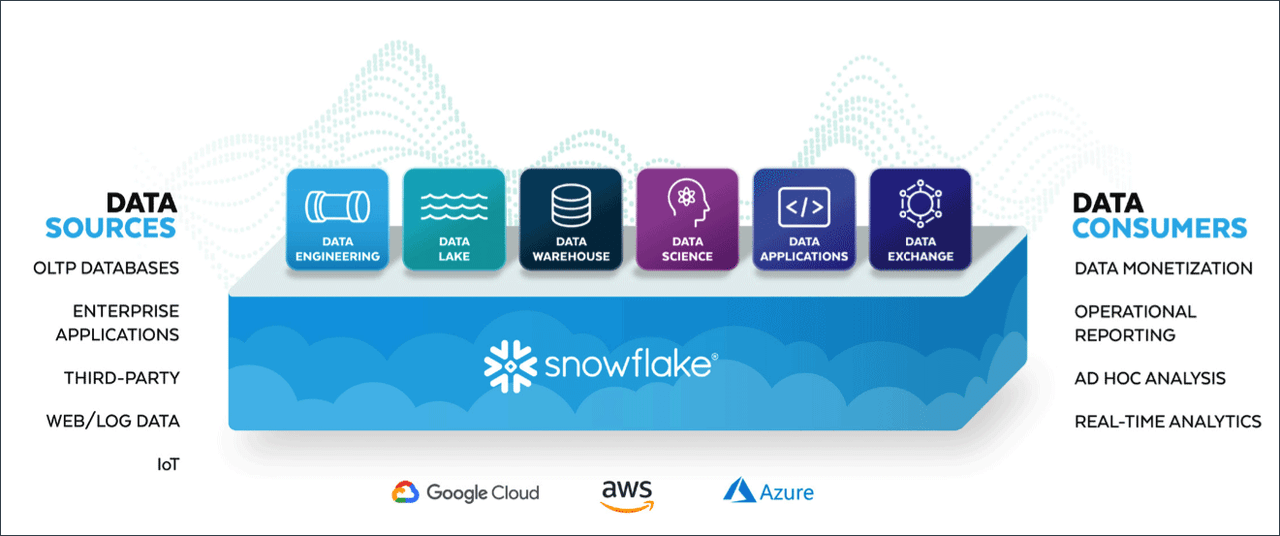
What is the Snowflake Data Cloud? - Analytics.Today
SNOW's core product is its CDW, which allows enterprises to copy data from various sources into one central warehouse for aggregated analytics. SNOW stores data, processes data into various forms, and facilitates queries of data for insights. These basic functions allow SNOW to offer higher-level products:
- Business intelligence for operational report such as aggregating the monthly sales of one region
- Transform saved datasets into a unified format for more insights
- Data science that exlores new valuable insights from existing data
- Data marketplace that allows enterprises to sell and share data
- Data apps that are built upon the data stored in SNOW
- Streaming data for highly time sensitive use cases
- Data lake for storing unstructured data that doesn't have immediate use case yet
Snowflake's Architecture
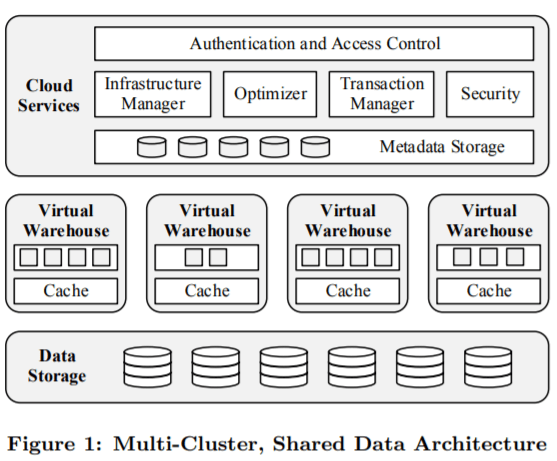
https://event.cwi.nl/lsde/papers/p215-dageville-snowflake.pdf
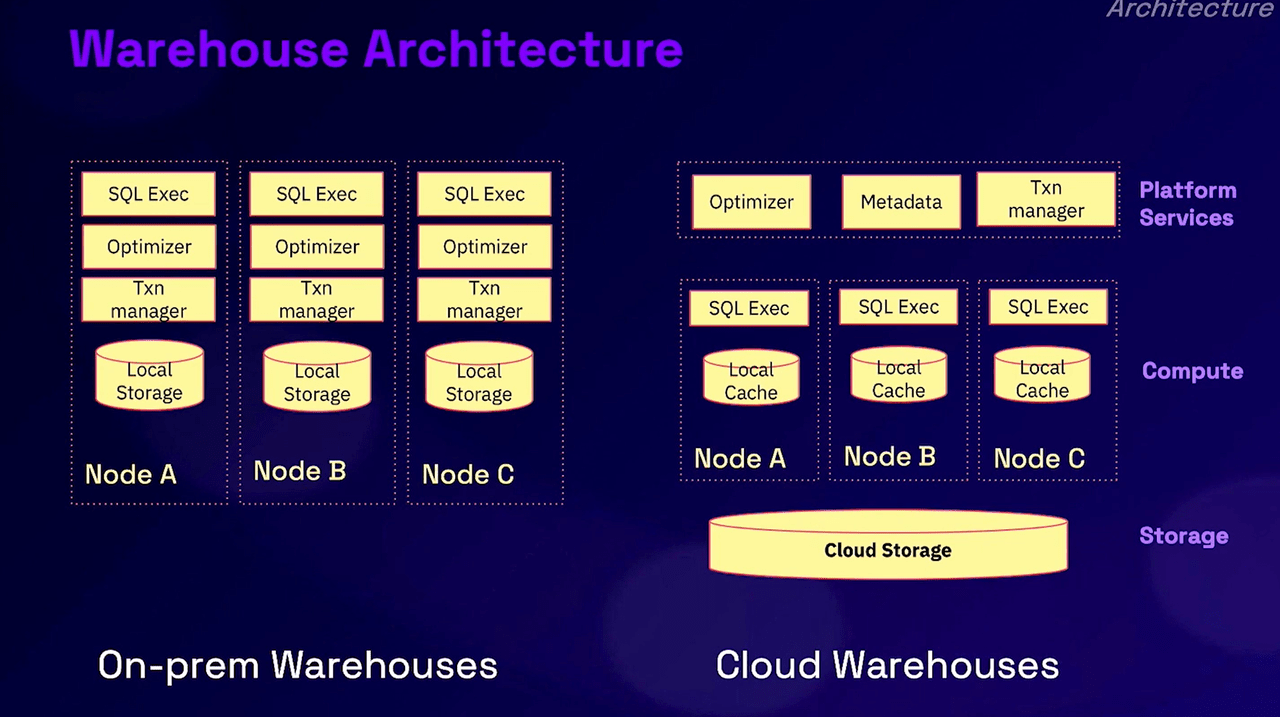
There are three major components within SNOW's architecture - cloud services layer, virtual warehouse (compute), and data storage (storage).
- All data is saved in the persistent data storage layer. SNOW uses object storage of hyperscalers' such as AWS's Simple Storage Service (S3), GCP's Google Cloud Storage (GCS), and Azure Blob Storage (ABS). Hyperscalers charge minimal fees for storing the data at rest.
- The cloud services layer saves metedata and key information. This is data that has multiple copies and needs to be live and highly available all the time (unlike persistent storage and virtual warehouses which are not 'alive' when not in use). It governs the overall access authentication and security of the system. It is also responsible for scheduling analytics jobs efficiently and reliably. Upon the new compute requgenerationsest, it optimises the job and schedules it according to the metadata.
- The Virtual Warehouses are the actual workers that handle the compute on demand. Enabled by hyperscalers' elastic VMs like AWS's EC2, SNOW is able to spin up huge numbers of these compute resources instantly. These distributed virtual warehouses then retrieve the data from persistent storage >>> store it in the local ephemeral storage, according to the schedule dictated by the cloud services layer >>> send back the results to persistent storage >>> and then immediately shut themselves down after the job is finished.
What's more special about SNOW's architecture is that it aims to maximise processing speed while also accommodating many data types. Unlike other data warehouses, SNOW can deliver query results within seconds, making it possible to be the foundation to build apps and even OLTP use cases on top. Additionally, SNOW's proprietary storage engine has strong ACID (Atomicity, Consistency, Isolation, & Durability) support, which basically means it not only has a strong capability to process data at scale, but can also process data with atomic granularity and high reliability. Via JSON extensions, SNOW also supports unstructured data by turning it into semi-structured with the use of the metadata. Again, these architectural innovations allow SNOW to build not only CDW but other services beyond and help it build out its vision of the data cloud.
Workloads
Most public investors view Redshift and BigQuery as primary competitors to SNOW on ad-hoc query workloads. And the general belief is that Databricks and Apache Spark are more of a collaborator rather than a competitor. Therefore, it is very important for us to understand the characteristics of SNOW's workloads to know who SNOW is competing with at the moment, and in the future. Fortunately, SNOW has the first party statistics here.
According to SNOW's 2020 paper (https://www.usenix.org/system/files/nsdi20-paper-vuppalapati.pdf), out of all customer queries:
- Read-only queries take up 28%. These are the typical ad-hoc and interactive OLAP workloads where the result is usually small in size, and is directly returned to the client. These types of queries spike up during the daytime hours on workdays.
- Write-only queries take up 13%. These are data ingestion queries that do not read any persistent data.
- Read-Write (RW) queries take up 59%. These are basically queries that RW to persistent data storage for ETL (Extract, Load, Transform) use cases.
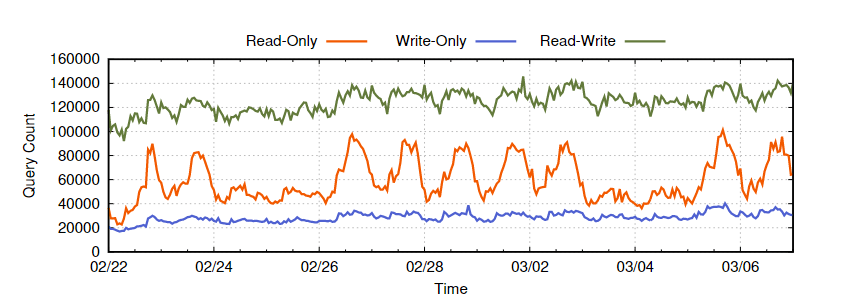
SNOW's statistics paint a very different picture to the general view that a data warehouse mainly handles the read-only queries for BI analysts. SNOW's workloads are very diverse and not confined in the traditional field of data warehouse only. ETL workloads are a huge part of SNOW's business, and as a result, vendors such as Databricks which handle the compute of data pipelines have more overlap with SNOW in terms of compute demand. There is also a substantial number of write-only tasks that constantly add new information to the CDW. Furthermore, the read-only workloads are way more spiky and time sensitive, which is closer to the streaming use case rather than batch processing tasks.
Business
Passing through the underlying storage pricing to the end user is a huge part of SNOW's strategy. SNOW charges $23 per month per TB, which is basically the same pricing as AWS S3 starting at $0.023 per GB per month. The caveat is that the terms vary with greater scale. On a certain scale, you will still hit the limit and have to negotiate a tailored quote based on a minimum spend (e.g., $10m minimum spending credit on AWS, paid upfront and non-refundable even if not used).
The default assumption of using a supercloud over the cloud is that the additional layer will add an additional intermediate fee on top of the underlying cloud spending. Though, by passing through the underlying object storage pricing directly to the end customers, SNOW soaks up the cloud services layer cost such as security and governance and the optimisation of metadata services. In exchange, this encourages enterprises to store as much data on SNOW as possible. Once customers view SNOW, instead of the hyperscalers' (or others) underlying object store, as the end storage layer, SNOW can leverage its central status to incur more demand for compute and/or data sharing.
SNOW's long-term gross margin target is 75%. This implies that, assuming all else equal, SNOW charges 4x that of the raw compute you would incur by using a complete DIY (do it yourself) data stack. Hence, SNOW's business model hinges on more CPU time spent on queries and processing data for customers. The fundamental driver of SNOW's business is more incoming data being loaded, transformed, and then queried via direct SQL, or applications using queries.
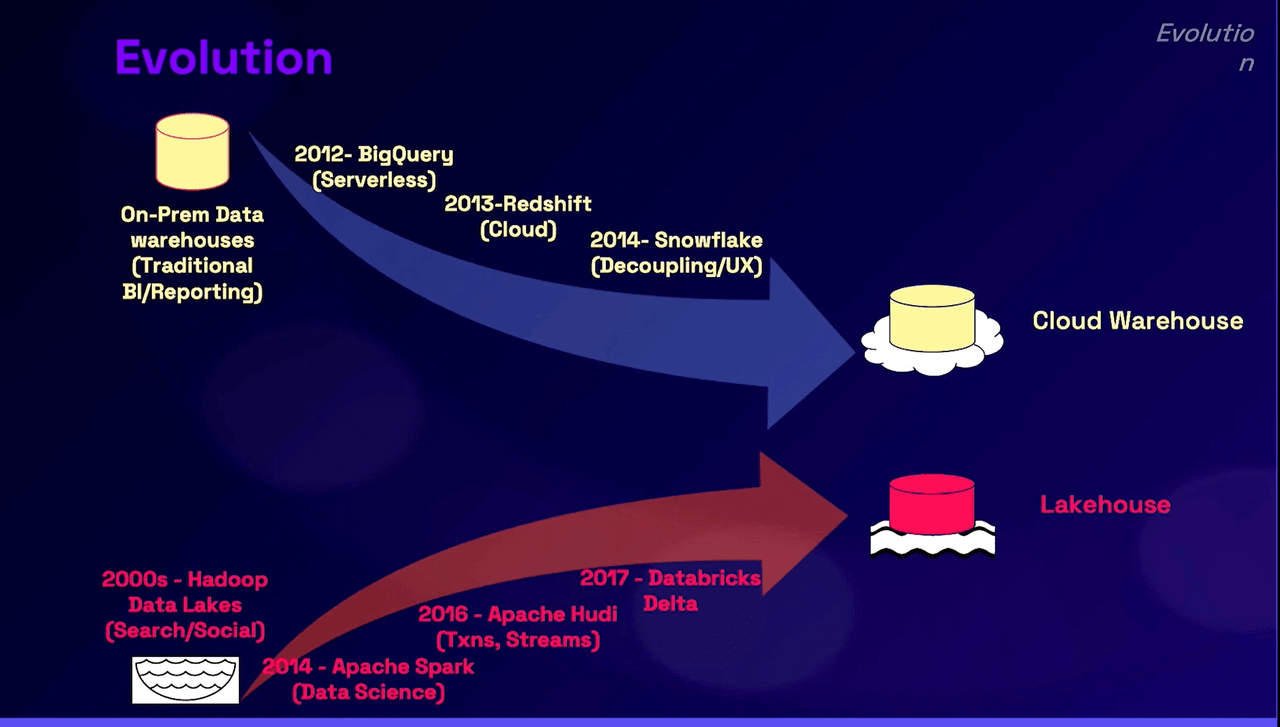
Data Warehouse, Data Lake, and Lakehouse
For less technical readers, let's have a quick recap of OLTP, OLAP, and the subsequent architectural move from the on-prem data warehouse, to the cloud data warehouse, data lake, and lakehouse.
https://www.cidrdb.org/cidr2021/papers/cidr2021_paper17.pdf
Data Warehouse to store curated data
The earliest form of database is the Online Transaction Processing (OLTP) database, which handles the transactional processing of daily business activities such as banking and airline ticketing. These OLTP databases are business critical as every single row records critical information such as one customer's bank account balance. Therefore, multiple backups to ensure high availability and high-speed lookup are required.
As data grows, and more applications are built using different OLTP databases, people started to propose Online Analytics Processing (OLAP) databases that could centralise data from various OLTP sources together to generate insights for business users to make better decisions. For example, one global bank may maintain an independent OLTP for each country's branch, and it is very desirable to build a centralised data warehouse to gather the information together to understand the total amount of monthly revenue.
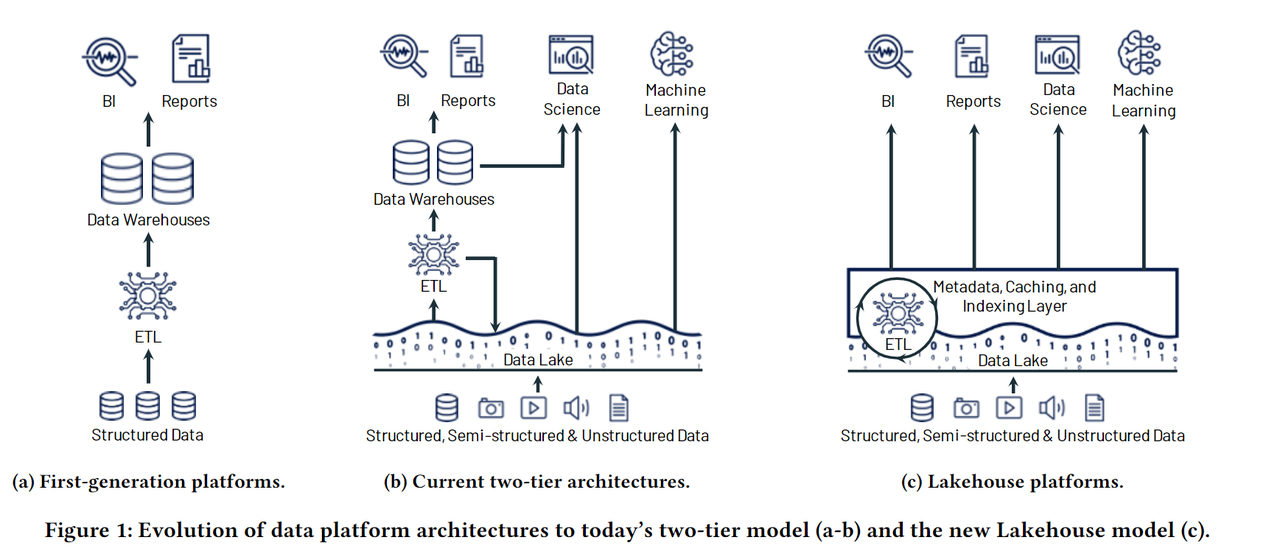
The first-generation platform emerged. Engineers extracted data from multiple sources, transformed it into a unified structure, and loaded it to the centralised data warehouse (ETL). With data being highly curated and processed into forms that business analysts can understand and use, end users could do queries to find business insights to drive more revenue or reduce costs, or generate monthly reports for the management team.
Data Lake to store all data
Coming into the early 2000s, the explosion of the Internet made data way more unstructured. Unlike the previous generations of OLTP being used in banking and more traditional industries, companies like Google and Yahoo experienced more unstructured data such as video, photo, audio, and text documents coming in. They needed to find a place to dump all of these data formats, and to subsequently find time to do ETL in order to transfer valuable information to the data warehouse, or use machine learning algorithms that can process and extract insights straight out of the unstructured data. Data lake emerged as a cheap way to centrally store all the data, curated or not.
A data lake serves as a patch to a data warehouse as the latter doesn't support saving unstructured data, and is often very expensive in terms of $ per GB of data stored. Furthermore, with the advent of machine learning algorithms that could read and process unstructured data, the data lake became a convenient storage layer for data scientists to use and explore new insights for new problems.
Lakehouse to consolidate the architecture
Data lakes fill in a much need gap but it adds complexity as the data team now have two sets of systems to manage and maintain. Coming into the 2020s, we are starting to see various vendors proposing the lakehouse concept or similar architectures to remove the redundant duplicative storage layer. The idea of the lakehouse is that there is one metadata, caching, and indexing layer, that can store structured and unstructured data in tandem.
This is made possible by the growing complexity and abstraction of the storage layer whereby an additional metadata layer is introduced between the compute and storage. Engineers can load all data into a lakehouse, transform and save the curated data, and simultaneously store the unstructured data that cannot be curated but consumed by ML algos. Upon usage, the metadata API can send curated ETL'ed data to warehouse engines and unstructured data to ML engines.
Through this method, the lakehouse eliminates the duplicative storage incurred when using a warehouse and a data lake.
Streaming and Batch
In contrast to OLTP, OLAP and the big data industry were built upon the assumption that timeliness isn't the top priority. OLTP typically requires millisecond-level response speeds, while OLAP use cases may range from minutes to days.
It turns out that staleness or freshness still matters a lot and will be even more critical in the future. For example, if you want to know what has been trending on Twitter during the past one hour, OLAPs that take more than one hour to query and summarise the data, would be obsolete.
Traditionally, the OLAP compute engine and storage layer are designed for batch processing, whereby thousands of records are processed at one time, resulting in high throughput and high latency.
Newer streaming architectures are eyeing the prospect of delivering OLAP features at sub-second speeds without huge sacrifices in throughput.
Ad-hoc queries sit somewhere in between streaming and batch processing. Batch processing is predominantly used in ETL whereby the data pipeline of ETL can be up and running for hours or even days. Ad hoc and interactive queries are meant to be finished within minutes or hours.
From On-Prem to Cloud Warehouse
A huge part of SNOW's success hinges on the notion of the Modern Data Stack (MDS) revolution, first introduced by AWS's Redshift and rapidly accelerated by SNOW and the subsequent new generation of disaggregated, specialised vendors in various components of MDS.
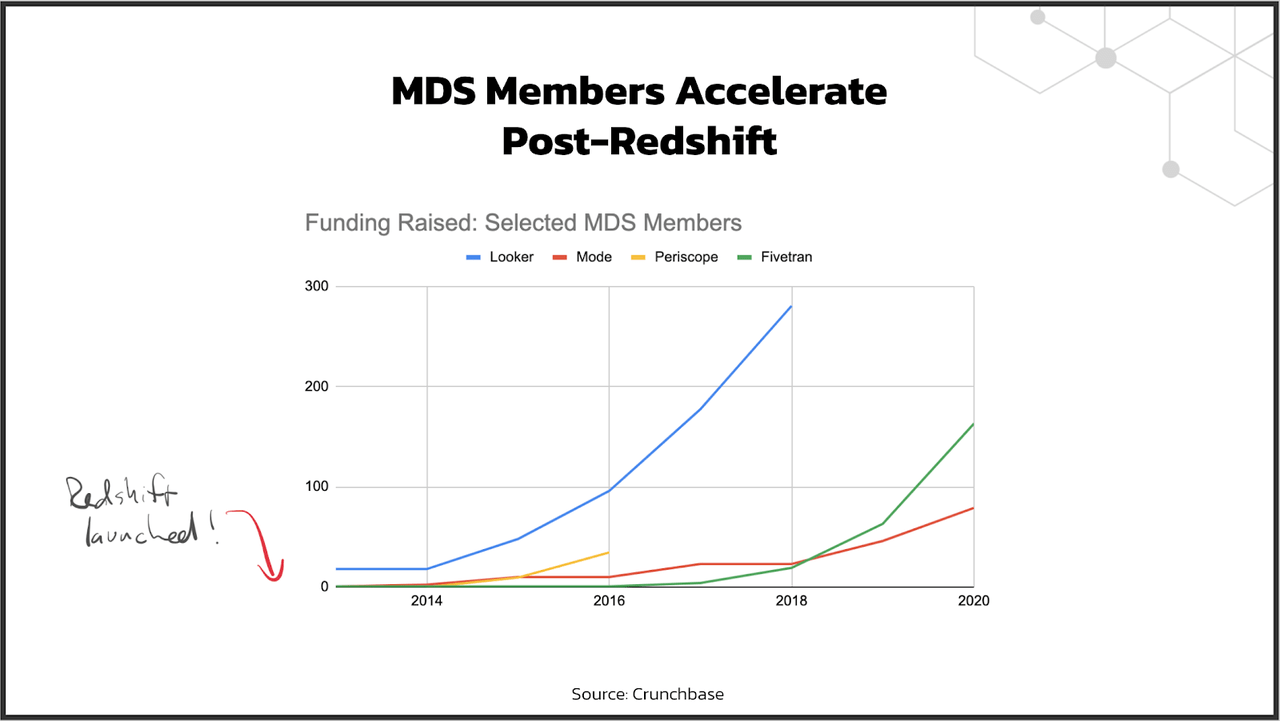
In 2020, Dbt's founder framed the emergence of MDS into three stages - Cambrian Explosion I (2012-2016), Deployment (2016-2020), and Cambrian Explosion II (2021-2025). Per this narrative, AWS's Redshift released in 2012 resembles the singularity moment that created many startups and cultivated the new foundation of cloud-native databases.
The biggest change brought in by AWS Redshift was the change from capex-heavy, inflexible consumption models, to opex-heavy, on-demand consumption models. In the previous world of on-prem data warehouses (TDC), you have to predict and invest huge amounts of resources for both peak storage and peak compute consumption. As you have seen from the previous SNOW usage chart, the computational need for queries can range in multiple orders of magnitude. This inelasticity, for the most part, results in a huge amount of idle capacity and only a very limited number of enterprises can afford this.
This is the perfect spot for the cloud to revolutionise, with its elasticity and high-speed interconnect as key features.
Lakehouse or Warehouse: Where Should You Live | Onehouse
Google's BigQuery is the earliest cloud-based data warehouse that made a buzz. Google has the best big data team, and it has developed tons of cutting-edge technologies used internally that lead the commercial market by 3-5 years.
BigQuery is GCP's core PaaS offering, whereby they leverage serverless technology and internal know-how to build a best-in-class data warehouse, especially in terms of performance. However, due to Google's culture and product management deficiencies, BigQuery has never gone mainstream, and is still a marginalised player, especially in the MDS movement where decoupling and third-party collaboration is increasing in importance.
Redshift kicked off the real boost to the industry with on-demand pricing and active ecosystem support. With Redshift and MDS startups, enterprises could get an OLAP in production within days and with a budget less than $10k. This is profoundly disruptive against the previous modus operandi, which consisted of spending over $1m on OLAP projects that would require a team of data engineers and still take more than a year to finish.
AWS' open approach and great partnership with innovative startups has always been a huge part of its DNA, leading to its dominance in IaaS against GCP and Azure, which actually have better raw technologies.
Redshift, however, hasn't fully leveraged the power of the cloud and popularised the concept of the Cloud Data Warehouse (CDW) in the same way SNOW has done. Redshift still requires tons of engineering know-how to operate it, and because of its inherent architecture, it is still priced with storage and compute tightly coupled together.
SNOW was the first to challenge the previous modus operandi - that is, compute has to be as close to storage as possible to achieve better performance and efficiency. The previous modus operandi on works in the on-prem world. In our previous AWS analysis, we've highlighted the pros and cons of the cloud. Cloud isn't outright better than on-prem in all aspects. In particular, on a per GB or per CPU performance perspective, AWS is 2-3x more expensive than on-prem. This is due to AWS' need to juice up a high gross margin, but also due to more auxiliary spending in excess over spending on the absolute necessities such as security, high-speed networking, and availability requirements. Though, the benefits of still opting for AWS can be summarised in the following formula:
Cloud ROI = benefits of elasticity, networking, and operations > costs of premium
SNOW broke the status quo of tightly coupled storage and compute with the use of S3 object storage, EC2, and high-speed networking within AWS. The end result is more than 10x reduction of storage costs with better performance. This is the fundamental driver of SNOW's rapid growth and also the MDS industry overall.
Aside from architectural leaps, SNOW also leveraged the as-a-Service trend in the SaaS industry. With better product design that emphasises ease of use and packaged software that minimises the need for configuration, SNOW is able to further penetrate into a wider customer base.
CDW ignited MDS
With SNOW's clearly better ROI and UX that gained easy support for both top-down decision-makers and bottom-up users, the on-prem software toolchain is subject to revolution as well. More notably, SNOW has taken an open approach to third-party tool integration, akin to, or even better than, AWS.
As a result, SNOW and Redshift have triggered an explosion of independent SaaS vendors focusing on one particular part of the data (OLAP) stack. The previously closely coupled data stack is completely decoupled and up for cloud-native vendors to grab. Furthermore, the new architecture of the CDW also gave rise to new spaces and stacks for more vendors to thrive.
There are various ways to categorise and map the MDS. Below is the way a16z mapped it in its Data Architecture Revisited: The Platform Hypothesis
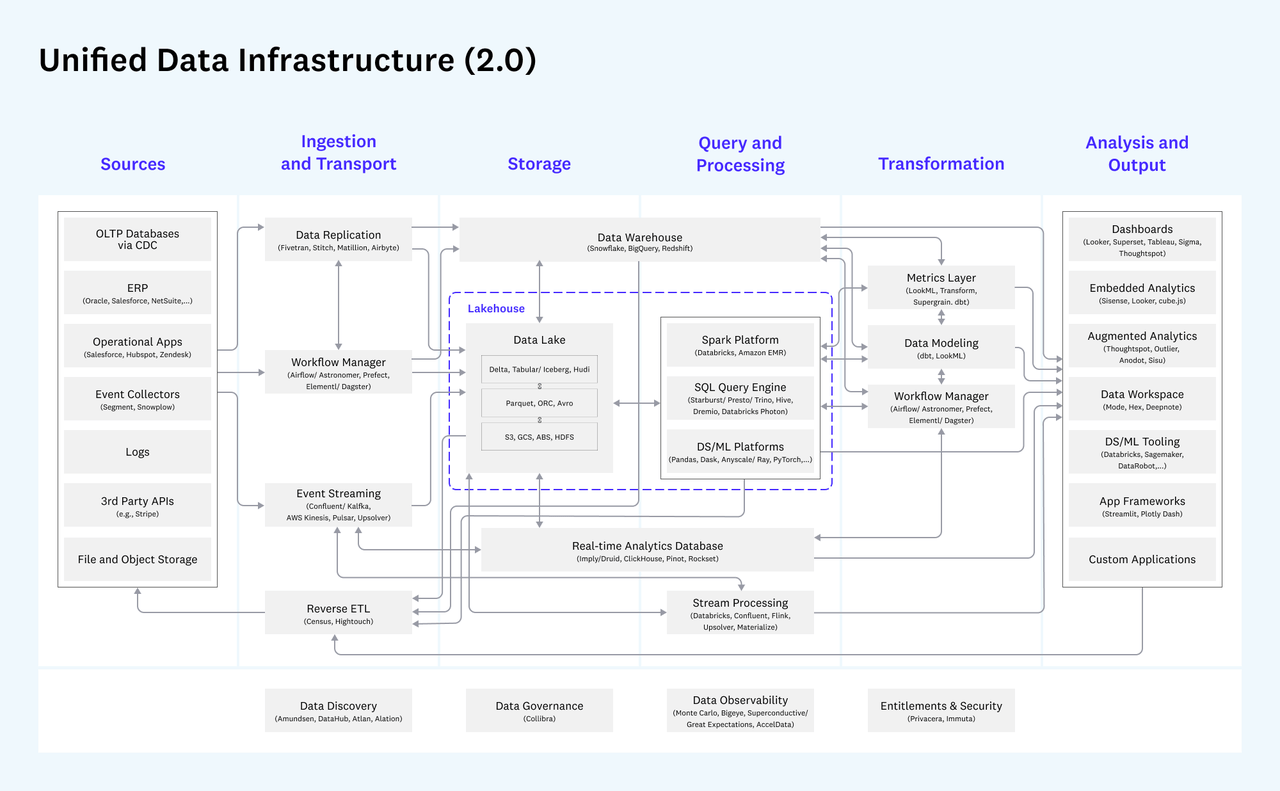
From left to right, you have
- data coming from various sources
- ingested and transported
- loaded to storage
- queried and processed
- transformed into various ways for easier understanding
- end usage for data visualisation, dashboard, etc.
Our version of understanding the MDS right now is that:
- OLTP >>> the database that is business critical, highly available and reliable, and with low latency
- OLAP >>> the database that is not directly linked to business functions, but has an emphasis on efficiency, scale, and operational ease of use
- HTAP (Hybrid Transactional and Analytical Process) >>> combining OLTP and OLAP together within one solution such that there is no need to export data from OLTP to OLAP.
MDS
- Get data (from OLTP to OLAP) >>> Extract, Load, and Transform (ELT)
- Store data >>> Metadata + Object Storage
- Compute data >>> querying and processing >>> batch or streaming or ad hoc / BI or data science / SQL or Python etc. / structured or unstructured
- Use data >>> BI / Metrics / Presentation / Reverse ETL / Data Apps
- Organise all of these >>> Process Orchestration Management + Governance + Observability
Storage
SNOW owns the storage and compute layer, and it also has barebone tools for getting data (Snowpipe) and using data (Streamlit). What this means is that once data is loaded into SNOW, it is very hard to get it out, even more so after you reach a certain scale. The data is stored in SNOW's proprietary format over the object storage of hyperscalers'.
The reasons for opting for the proprietary format route are due to a lack of an open-source warehouse storage engine taking advantage of cloud object storage, and due to SNOW's need to do heavy optimisation internally to store data more efficiently (saving cost) and more performantly (reduce compute time).
After the the initial success of CDW, there were multiple open source projects that targeted building a metadata layer on top of object storage. Most notably, there are:
- Apache Hudi, initially open sourced by Uber and now led by Onehouse as the commercial entity backer. Closely coupled with Apache Spark as the compute engine. Mostly for streaming use cases.
- Apache Iceberg, initially open sourced by Netflix and now led by Tabular as the commercial entity backer. Great support for all compute engines with support for diverse use cases due to its more well-thought out architecture.
- Delta Lake, initially (and partially) open sourced by Databricks and just recently fully open sourced (in June 2022) to the Linux Foundation. This is largely driven by the mounting competitive threats from Iceberg. Due to its Databricks root, it is highly coupled with Apache Spark with several functions proprietary to Spark only. It is mostly used for batch processing for data science use cases.
These storage engines offer an attractive open source alternative to SNOW, Redshift, BigQuery, and overall CDW architecture that have storage and compute dependency tightly coupled.
Sidenote: here we say that SNOW couples storage and compute in the sense that customers that use SNOW must use its storage and compute - meaning customers can't use third-party compute engines while using SNOW for storage. We will dive into the pros and cons, from both SNOW's and the customer's persepective, in Part 2.
However, SNOW is moving rapidly to incorporate the support of Iceberg as the external source of storage, now that Iceberg has become a first class citizen within SNOW. We believe that Iceberg seems destined to be the future open-source winner at the storage layer, while a big majority of customers will still go with SNOW's proprietary format for performance and data sharing use cases. We will be analysing this further in Part 2.
Compute
Compute is probably at the centre of MDS right now and in the near future. We've divided specific technologies and the companies behind them in their business criticality and timeliness. Snowflake mostly plays in the ad-hoc and batch-processing space. 59% of SNOW's workload is around ETL related to batch processing that is very time insensitive and larger in scale. These are typically recurring jobs coded by data engineers who built the data pipelines. 28% of SNOW's workload is around the actual queries run by business analysts who run the query to know the results they need during their working hours.
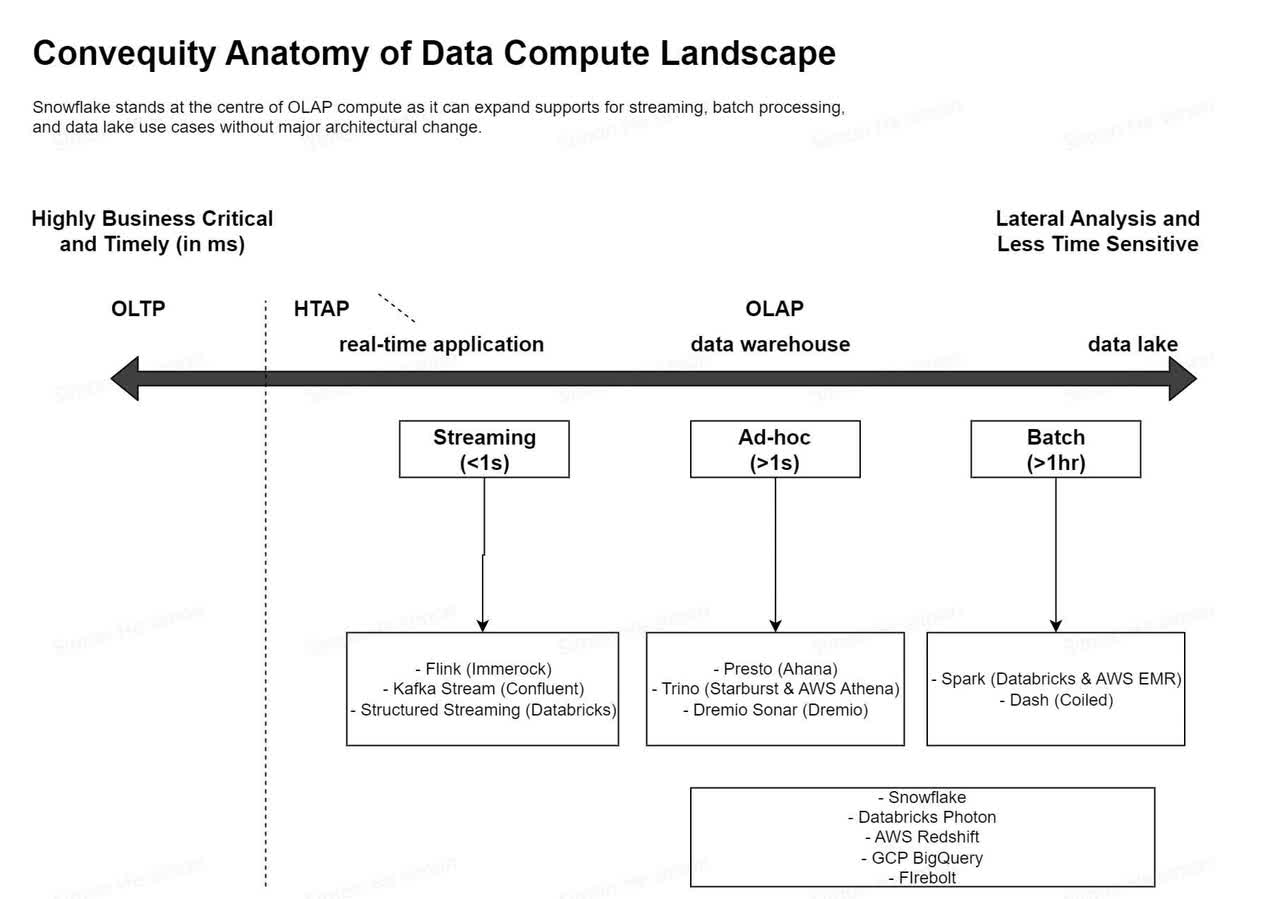
Source: Convequity
SNOW's most immediate competitors in this space are Spark and Trino.
Apache Spark was created by 7 Phd students from the University of California at Berkeley's RISElab, who were initially working on developing a next generation Hadoop. Hadoop was the first generation big data system, open sourced by Yahoo, in an effort to leverage the COTS (Commodity Off The Shelf) x86 machines. x86 machines are less capable at the individual machine level in regards to the maximum storage and compute available within one server. Due to x86's consumer root, they are also less reliable for production environments that require the machine to run flawlessly 24/7. However, from a per unit storage & compute perspective, x86 is substantially cheaper than specialised machines by 5x or even higher. By building an orchestration software layer that can spread compute and storage to multiple x86 machines, and automatically correct the issue when one node fails, enterprises can make huge cost savings and make general x86 machines more usable for other use cases.
Spark is the most popular compute platform to manage distributed compute. Although Spark was designed initially for academic and data science usage, in more than 70% of its use cases it is used for SQL and Business Intelligence - meaning there is a significant overlap with SNOW. Right now, most customers use Spark for ETL data preprocessing and running Python and other non-SQL languages for data science projects. Spark doesn't handle SQL ad-hoc queries well, and that's the place where SNOW jumps in, and the reason behind why they collaborated on 80% of deals.
It is to be noted that Spark was heavily designed for highly sophisticated engineering teams, and even big enterprises with large engineering teams find it hard to use. As a result, Databricks created its own proprietary Databricks Spark that is provided as a service hosted on hyperscaler clouds. This version covers tons of engineering intricacies under the hood and allows enterprise users to have the out-of-the-box functionality without the huge engineering effort. It also made Spark less open as more advanced features have been kept closed source by Databricks.
A more popular version of Spark-as-a-Service is AWS EMR. AWS handles the heavy duty work of operating Spark and provides a managed open-sourced version of Spark as the end service. Furthermore, by using cloud formation templates, customers can quickly create a data lake + EMR + lambda based serverless pipeline. This is only possible on AWS where the more mature and comprehensive as-a-Service components are available, and when needed, Databricks and Snowflake on AWS can be cross-sold.
Apache Trino was originally created by Meta's engineers who wanted to build a MPP (Massively Parallel Processing) ad-hoc query engine for their massive PB scale infrastructure. Compared to Spark, that has more generic use purpose, Trino is more targeted, performant, speedy, and cost-effective, but less capable in non-ad-hoc query use cases such as ETL data pipeline and jobs that takes hours to run. Starburst is the commercial entity created by Trino creators, and they are also expanding very fast with a totally managed service on AWS. With Trino on compute plus Iceberg on storage, enterprises could assemble a more open and cost effective version of SNOW at the cost of more engineering work and maintenance.
To a lesser extent, we see Databricks Photon, Dask, Dremio, and Flink as potential alternatives to SNOW.
Photon is Databricks' natural evolution into a pure data watehouse compute engine to work with its Delta Lake, that together features a lakehouse architecture. Basically, Databricks saw the need to build a dedicated compute and storage stack for data warehouse. Opting to leverage and tweak its existing data lake architecture wasn't going to work for customers that need strong SQL and CDW functionality. Databricks has intentionally kept Photon closed source and available as-a-Service only. We will be providing more colour in the Part 2, but it does represent strong competition to SNOW in the future, something we sense that public investors haven't given enough attention to.
Although Spark is for data science, it was originally written in Scala instead of Python, the de facto language for data science and ML engineers. We believe Dask, which is Python native, has a substantial opportunity to overtake Spark as the next-gen distributed compute platform. Coiled is the commercial entity behind it and we do agree with their claim that Spark is somewhat aging and requires more overhead to run. As ML is quickly maturing, and Dask could be the desired compute engine for it, it presents substantial completion to SNOW in the future.
Dremio is another aggressively emerging data warehouse compute engine, which is similar to Databricks Photon. The team is very focused on making every possible slither of optimisation to deliver the best performance and efficiency. Unlike Photon, however, it is open source and the team has also made substantial contributions to the Iceberg project.
Finally, Apache Flink, as the streaming focused compute engine, has way more potential in the future as people are trying to incorporate ACID transactions on the data lake so that OLTP and OLAP can be used together. Flink + Hudi is already heavily used by vendors like Uber and Bytedance (TikTok) who have use cases akin to OLTP. For example, Uber used it to calculate the estimated arrival time of a taxi, which is not a critical OLTP, but also not purely OLAP neither, as the timeliness and accuracy matters a lot to end users. SNOW isn't the direct competitor at the moment. However, as SNOW expands into more data application use cases in the future, we believe inevitably this will be another potential competitor.
Based on our findings, most vendors have recognised the need to provide as-a-Service offerings and make the product as easy to implement and use as possible. They have also adopted massive parallelism and leveraged key foundational acceleration techniques such as separation of compute and storage, SIMD (Single Instruction Multiple Data), data skipping, and predicate pushdown. As such, we don't believe the key advantages, such as separation of storage and compute and the cloud-native architecture, mentioned by most public analysts, hold true for the latest generation of compute vendors versus SNOW.
What will define the long-term success in this space will likely reside more in the architectural tradeoffs, such as open verus closed, and is not likely to be a winner- takes- all scenario. We will be providing our judgement on each vendor's performance claims, their competitive positions, and the data ecosystem future in Part 2.
ELT
ETL is another huge part of the MDS value chain. Historically, because on-prem DW have had limited compute resources, you have to normalise the dataset in advance to avoid computational overhead when queried. Following the CDW disruption, we are now seeing data ingestion (extract and load) and transformation being decoupled and provided as SaaS tools that reduce this overhead by being easier to operate, evolve, and collaborate with.
Fivetran is the de facto leader in data ingestion, but Airbyte and others are catching up. Data ingestion is a huge part of the MDS as it prevents data silos and is responsible for connecting disparate systems. It is also a huge part of PLTR's and Cohesity's moat.
dbt seems to be the monopoly in the transformation space due to its open source approach. For many years, dbt was the only option when modeling and transforming data on SNOW and Redshift. This is further compounded by its open source feature sourcing that makes dbt even easier to use. SNOW is less likely to go into this space and its open approach has helped dbt to beat the on-prem tool chain.
Integrative and specialised players
As SNOW is actively expanding into specific verticals like cybersecurity, and more expansive use cases like data apps, it is also worth noting several adjacent competitors.
SentinelOne (S), Palo Alto Networks (PANW), and CrowdStrike (CRWD), are probably the three most notable competitors to SNOW in the security MDS space.
S has a very efficient and performant data backend called DataSet, which comes from an acquisition from a startup called Scalyr. In our previous S analysis (a deep dive in April 2022), we explained how DataSet has impressive technology that leverages the separation of compute and storage like SNOW does. Scalyr's founder was heavily involved in Google's big data team in designing performant and efficient data storage and querying systems. Most notably, S security data backend is able to deliver real time alerts at PB scale, which is 10-100x faster than SNOW. Combined with its impressive XDR technology that together forms an integrative security SaaS and data back-end bundle that is effective and cheap compared to disjointed alternatives, we believe it is a very strong rival against SNOW + security data startups such as Panther Labs.
PANW is another early proponent of the security data lake, beginning its development back in c. 2018. It has relatively more focus over the application of security data, and is relatively weaker in the data backend. Most notably, its recent announcement of XSIAM, an integrated platform that handles security data ingestion, data management, data querying, data processing, as well as the end-user alert generation, automated response, and guided processes for SOC analysts, resonates strongly with end customers.
SNOW may potentially have a better data backend than PANW. However, given PANW's connection with Google talents who are excellent at engineering data systems, and PANW's stronger edge on the cybersecurity aspects, we believe SNOW will face a tough fight when selling its products to big enterprise security teams.
CRWD is potentially a weaker player. In early 2021 (about the same time S acquired Scalyr), it acquired a log management vendor named Humio, which has an architecture more similar to SNOW's. CRWD's EDR-turned-XDR has less focus on the timeliness of data processing and querying. This is also due to its past technical debt as CRWD was previously partnered with SPLK in operating a SIEM infrastructure backend.
Palantir (PLTR) is not a direct competitor to SNOW at the moment. Right now, PLTR could run and manage SNOW as part of its data platform. However, if SNOW is going to expand into a data application world in which military, intelligence, public sector, and multi-national enterprises are huge parts of the market, PLTR is a strong competitor. Most notably, PLTR has its entire MDS built in-house, from Software-Defined Data Ingestion, to storing data both in edge, cloud, and air-gapped systems, to querying everywhere confidentially and implementing ML in production, to the end use of data visualisation and presentation. Furthermore, PLTR's Forward Deployed Engineer (FED) model combined with 80% Gross Margin showed its ability to deliver complex engineering projects for end customers without huge operational overhead. This is an extremely deep moat for SNOW to compete against in the future.
Cohesity was founded by an ex-Google engineer who masterminded its global distributed data file system. It was initially targeting data backup and security use cases. However, the founder's vision is to do more with this backed-up data in the future. Instead of bringing in data to compute, Cohesity wants to allow developers to deploy applications on the centralised data system. Apparently, this clashes with SNOW's future vision as well.
Notable competition ahead
To conclude, we believe the public investors' view on SNOW is lacking substantial comprehensiveness. Considering SNOW's premium valuation right now, we believe the market is pricing in as if there is no competitor to SNOW in the market right now. This is true to some extent as the biggest direct competitor, AWS Redshift, has shifted from being a direct competitor to being a coopetitor. AWS' sales team is now making easy wins with SNOW + other AWS products. However, we would like to note to investors that, per our analysis above, there is a substantial number of next-gen vendors competing with SNOW with a level playing field in terms of raw technology.
We will be diving deeper into SNOW's performance and architectural differences versus the competition. We will also be analysing various storage and compute vendors' marketing claims, and give our judgement on where the industry will be evolving in the future in Part 2 of the analysis.



Comments ()